
耗時 2 年,Meta 聯手 CMU 打造最強” 通用機器人智能體 “!

在邁向 “通用機器人智能體” 的路上,Meta、CMU 團隊耗時 2 年打造的 RoboAgent,用少量數據實現 12 種複雜技能,烘培上茶擦桌子樣樣行。
爆火的大模型,正在重塑「通用機器人智能體」的研究。
前段時間,谷歌 DeepMind 推出了耗時 7 個月打造的項目 RT-2,能數學推理、辨認明星,在網上爆火了一把。

除了谷歌,來自 Meta、CMU 的研究人員用了 2 年的時間,打造出史上最強的通用機器人智能體「RoboAgent」。
不同的是,RoboAgent,僅在 7500 個軌跡上完成了訓練。

具體來説,RoboAgent 在 38 個任務中,實現了 12 種不同的複雜技能,烘培、拾取物品、上茶、清潔廚房等等。
甚至,它的能力還能夠泛化到 100 種未知的場景中。
可以説,上得了廳堂,下得了廚房。

有趣的是,不論你怎麼幹擾它,RoboAgent 依舊設法去完成任務。

RoboAgent 究竟還能做什麼?
烘焙、上茶、擦桌子全能手
首先,RoboAgent 可以很流暢地拉開或關上抽屜。
雖然在打開時險些碰倒了酸奶,但動作的銜接上基本沒有卡頓,絲滑地完成了推拉的動作。

除了抽屜,RoboAgent 還能輕鬆打開或關上微波爐的門。
但它沒有像人類一樣抓握把手,而是將自己卡進了把手與門之間的空隙中,再使力開合了微波爐的門。

同樣地,面對瓶瓶罐罐上的蓋子,RoboAgent 也能精準拿捏,打開、蓋上——絕不拖泥帶水。
然而在廚房中,除了蓋着的調料罐,也有一些需要擰開的罐子,比如料酒和老乾媽等等....

好在,對於各種拾取和放置類任務,RoboAgent 基本是不在話下的。
視頻中,RoboAgent 從抽屜裏拿出東西、又或是把茶包放進杯子裏,打開微波爐將碗放進去等。展示的便是 RoboAgent 能夠理解泡茶、加熱食物等任務中包含的一系列動作。

對以上九個動作進行排列組合,基本就可以覆蓋在廚房中一系列任務。
例如為烘焙做準備、打掃廚房、上菜湯、泡茶、收納餐具等。
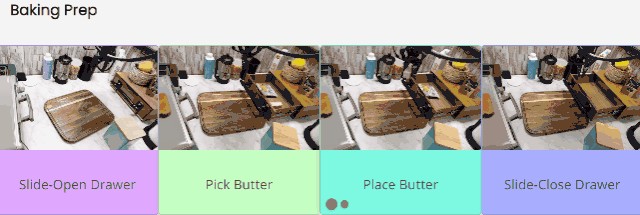
為烘焙做準備時,首先要拉開抽屜,然後找到放在裏面的黃油。找到後把黃油放到案板上,最後關上抽屜。
看起來 RoboAgent 這一系列動作的前後邏輯順序已經和真實的生活場景十分接近了。
但 RoboAgent 依舊不像人類一樣靈活,先不提人類有兩隻手,可以一隻手拿黃油,另一隻手關抽屜。就算只用一隻手,人類也可以拿着黃油的同時側手把抽屜推回去。而 RoboAgent 只能先把黃油放下,然後才去關抽屜。
看起來沒有那麼靈活的樣子。
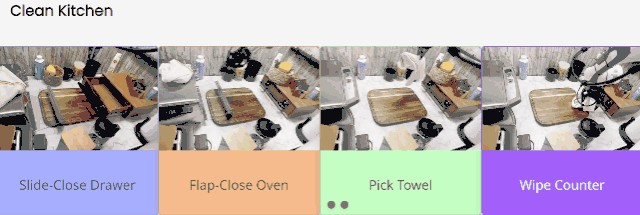
打掃廚房時,RoboAgent 也是四步走:
先關上抽屜,再關上微波爐。然後從旁邊拿出一個毛巾,最後擦案板。

上菜湯時,RoboAgent 先打開微波爐,然後從微波爐裏拿出放在裏面的碗。之後把碗放在桌子上,最後把微波爐關上。
但這裏 RoboAgent 的表現就沒有那麼讓人放心了。
只能説還好演示視頻中的碗是空的,如果真讓 RoboAgent 這樣在現實中拿裝了食物的碗盆,估計它剛拿起來食物就灑地到處都是了。
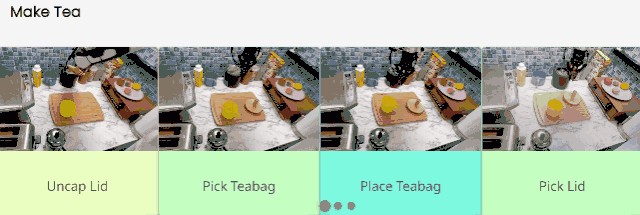
不過,RoboAgent 對泡茶倒是得心應手:
先取開茶罐上的蓋子,從裏面拿出茶包,然後把茶包精準降落在杯子裏,最後撿起蓋子放回到罐子上。
但這離完美的一杯茶還差了一步:倒水。還是説 RoboAgent 是在請我們喝有茶香的空氣嗎?
縱觀上述 RoboAgent 的表現,雖然大部分任務都能順利完成,但只有一隻手還是太不方便了。
希望 Meta 和 CMU 能多給 RoboAgent 安幾隻手,這樣它就能同時幹好幾件事,大大提高效率。

耗時 2 年,打造「通用機器人智能體」
Meta 和 CMU 的研究人員希望,RoboAgent 能夠成為一個真正的通用機器人智能體。
歷時 2 年,他們在不斷推進這一項目的前進。RoboAgent 是多向研究的集合體,同時也是未來更多研究方向的起點。
在「通用機器人智能體」發展過程中,研究人員深受許多最近可泛化的機器人學習項目的啓發。
當前,在邁向通用機器人智能體路上,需要解決兩大難題。
一是,因果兩難。
幾十年來,擁有一個能夠在不同環境中操縱任意物體的機器人一直是一個遙不可及的宏偉目標。部分原因是缺乏數據集來訓練這種智能體,同時也缺乏能夠生成此類數據的通用智能體。
二是,擺脱惡性循環。
為了擺脱這種惡性循環,研究重點是開發一種有效的範式。
它可以提供一個通用智能體,能夠在實際的數據預算下獲得多種技能,並將其推廣到各種未知的情況中。

論文地址:https://robopen.github.io/media/roboagent.pdf
根據介紹,RoboAgent 建立在以下模塊化和可補償的要素之上:
- RoboPen:
利用商品硬件構建的分佈式機器人基礎設施,能夠長期不間斷運行。
- RoboHive:
跨仿真和現實世界操作的機器人學習統一框架。
- RoboSet:
一個高質量的數據集,代表不同場景中日常對象的多種技能。
- MT-ACT:
一種高效的語言條件多任務離線模仿學習框架。它通過在現有機器人經驗的基礎上創建一個多樣化的語義增強集合來倍增離線數據集,並採用一種具有高效動作表示法的新型策略架構,以在數據預算範圍內恢復高性能策略。

動作分塊,全新架構 MT-ACT
為了學習通用的操作策略,機器人必須接觸豐富多樣的經驗,包括各種技能和環境變化。
然而,收集如此廣泛的數據集的操作成本和現實挑戰,限制了數據集的總體規模。
研究人員的目標是通過開發一種範式來解決這些限制,該範式可以在有限的數據預算下學習有效的多任務智能體。
如下圖所示,Meta 和 CMU 團隊提出了 MT-ACT,即多任務動作分塊 Transformer(Multi-Task Action Chunking Transformer)。

這一方法由 2 個階段組成:
第一階段:語義增強
RoboAgent 通過創建 RoboSet(MT-ACT)數據集的語義增強,從現有基礎模型中注入世界先驗。
由此產生的數據集,可在不增加人類/機器人成本的情況下,將機器人的經驗與世界先驗相乘。
然後,研究人員使用 SAM 分割目標對象,並將其語義增強為具有形狀、顏色和紋理變化的不同對象。
第二階段:高效的策略表示
生成的數據集是多模態的,包含豐富多樣的技能、任務和場景。
研究人員將動作分塊適應於多任務設置,開發出 MT-ACT——一種新穎高效的策略表示,既能攝取高度多模態的數據集,又能在低數據預算設置中避免過度擬合。
如下,是 MT-ACT 策略的各個組成部分。
RoboSet數據集
研究的目標是建立一個數據高效的機器人學習範例,對此,研究人員將自己限制在一個凍結的、預先收集的小型但多樣化的數據集上。
為了捕捉行為多樣性,研究人員還在不同的廚房場景中,將不同的技能應用到不同的任務中。
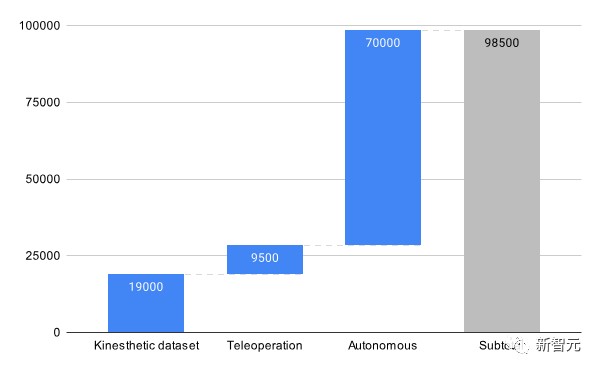
在這個項目中,數據集 RoboSet(MT-ACT)由人類遠程操作收集的 7500 條軌跡組成。
該數據集包含 12 種技能,橫跨多個任務和場景。
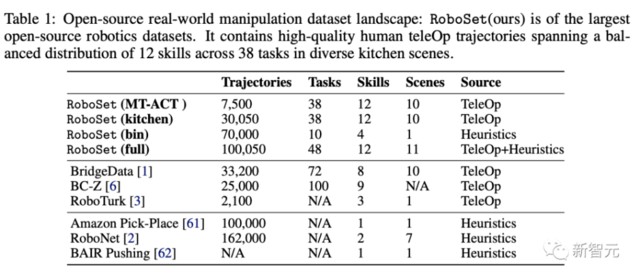
下圖顯示了,數據集中技能的分佈情況。
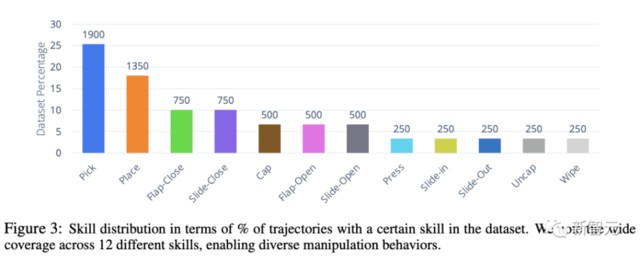
雖然常用的「拾取 - 放置」技能在數據集中佔 40% ,但也包括豐富的接觸技能,如擦拭、蓋帽,以及涉及鉸接物體的技能(翻轉 - 打開、翻轉 - 關閉)。
研究人員在 4 個不同的廚房場景實例中收集整個數據集,這些場景中包含各種日常物品。
此外,團隊還將每個場景實例與不同變化的物體進行交換,從而讓每個技能接觸到多個目標物體和場景實例。
數據增強
由於收集的數據集無法滿足對場景和物體多樣性的需求,因此研究人員通過離線添加不同變化的場景來增加數據集,同時保留每個軌跡中的操縱行為。
基於最近在分割和局部重繪(inpainting)模型取得的進展,研究人員從互聯網數據中提煉出真實世界的語義先驗,以結構化的方式修改場景。

MT-ACT架構
MT-ACT 的策略架構設計為一個有足夠容量的 Transformer 的模型,可以處理多模態多任務機器人數據集。
為了捕捉多模態數據,研究人員沿用了之前的研究成果,加入了將動作序列編碼為潛在風格嵌入式 z 的 CVAE。
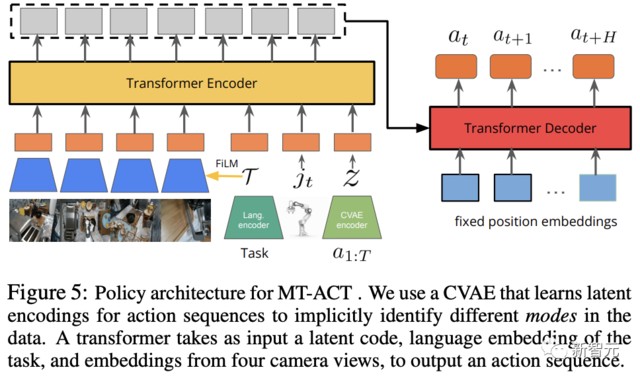
為了建立多任務數據模型,研究採用了預訓練的語言編碼器,該編碼器可學習特定任務描述的嵌入。
為了減少複合誤差問題,在每個時間步預測未來 H 步的行動,並通過對特定時間步預測的重疊行動進行時間平滑來執行。
另外,為了提高對場景變化的穩健性,研究人員通過 4 個拍照角度為 MT-ACT 策略提供了工作空間的四個不同視圖。

Transformer 編碼器以當前的時間步長、機器人的當前關節姿態、CVAE 的風格嵌入 z,以及語言嵌入 T 作為輸入。
然後,再使用基於 FiLM 的調節方法,以確保圖像 token 能夠可靠地集中在語言指令上,從而在一個場景中可能存在多個任務時,MT-ACT 策略不會對任務產生混淆。
編碼後的 token 將進入具有固定位置嵌入的 Transformer 策略解碼器,最終輸出下一個動作塊(H 個動作)。
在執行時,研究人員會對當前時間步預測的所有重疊操作,取平均值(當 H > 1 時,行動塊會重疊),並執行產生平均後的行動。
少量數據,趕超谷歌 RT-1
MT-ACT 策略在真實世界表現如何?
研究人員通過實驗評估了提出的框架樣本效率,以及智能體在不同場景中的通用性。
下圖,將 MT-ACT 策略與常用的模仿學習架構進行了比較。
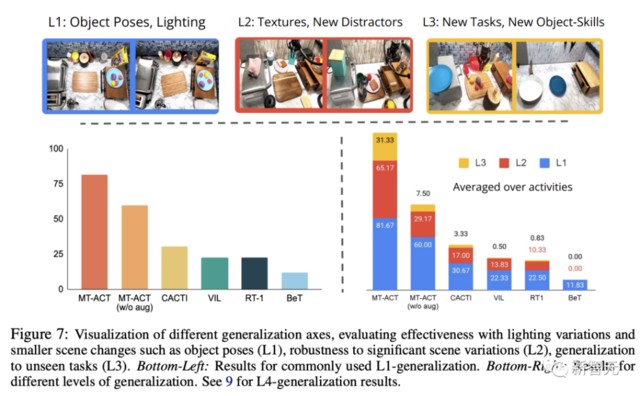
研究人員只繪製了 L1 泛化的結果,因為這是大多數其他模仿學習算法使用的標準設置。
從圖中可以看出,所有隻模擬下一步行為(而不是子軌跡)的方法都表現不佳。
在這些方法中,研究人員發現基於動作聚類的方法(BeT)在多任務設置中的表現要差得多。
此外,由於研究採用的是低數據機制,需要大量數據的類似 RT1 的方法在這種情況下表現不佳。
相比之下,MT-ACT 策略使用動作檢查對子軌跡進行建模,其表現明顯優於所有基線方法。
圖 7(右下)顯示了跨多個泛化級別(L1,l2 和 L3)的所有方法的結果。
此外,研究人員還分別報告了每種活動的泛化結果。從圖 8 中可以看到,每種語義增強方法都對每種活動的性能產生了積極影響。
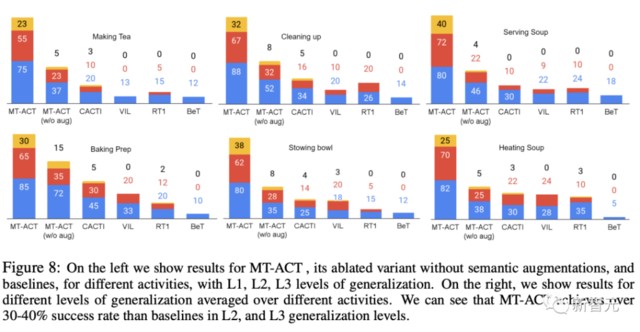
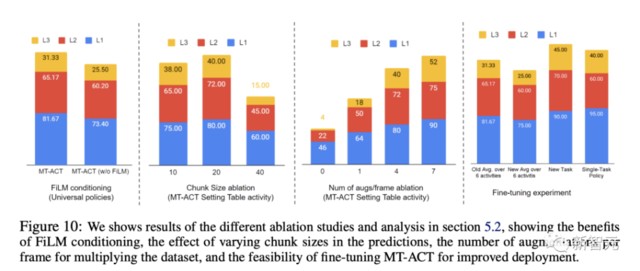
最後,研究人員還利用不同的設計來對架構進行了研究,比如動作表示塊的大小、可塑性、穩健性。
本文來源:新智元,原文標題:《耗時 2 年,Meta 聯手 CMU 打造最強「通用機器人智能體」!上茶擦碗多面手,輕鬆泛化 100 多種未知任務》
