
Google Gemini 3.0 Pro model card released, with multimodal capabilities significantly ahead of competitors

The model card shows that Gemini 3 Pro supports a context window of up to 1 million tokens and can output 64K tokens. It performs exceptionally well in logical reasoning tests for image understanding and achieved full marks in high-difficulty math rankings such as AIME 2025 in code execution scenarios. Analysis suggests that while it has not completely surpassed competitors in coding capabilities, Gemini 3 Pro significantly leads in multimodal capabilities and text RAG capabilities. Combined with Google's own search, Workspace, and Android ecosystem, it is expected to greatly enhance market expansion capabilities in scenarios such as search AI model commercialization, document Q&A, and enterprise AI
Google's next-generation large model Gemini 3.0 is about to be launched, with the official website first releasing the Gemini 3 Pro model card, showcasing significant breakthroughs in key areas such as multimodal processing, mathematical reasoning, and long text understanding.
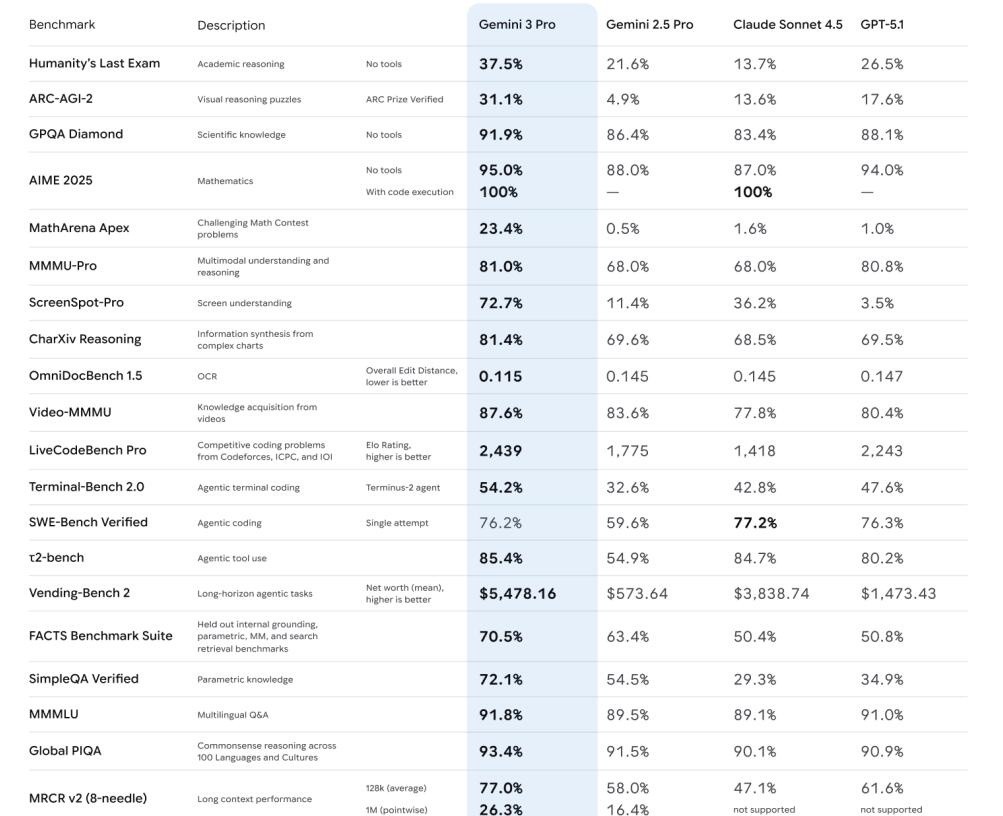
According to the comparative test data disclosed by the official source, Gemini 3 Pro significantly outperformed existing flagship models such as Gemini 2.5 Pro, GPT-5.1, and Claude Sonnet 4.5 in multiple benchmark tests.
The model card shows that Gemini 3 Pro adopts a sparse mixture of experts architecture, supporting a context window of up to 1 million tokens and capable of outputting 64K token text content. The model excelled in logical reasoning tests for image understanding, achieving full marks in high-difficulty mathematical rankings like AIME 2025 under code execution scenarios, demonstrating its top-tier capabilities in tool invocation and mathematical reasoning.
In professional application tests, experiments by Mark Humphries, a history professor at Laurentian University in Canada, indicated that the model achieved a character error rate of only 0.56% in recognizing 18th-century handwritten manuscripts, an improvement of 50%-70% compared to previous products, reaching expert-level human performance. This breakthrough performance has drawn attention in the industry regarding the qualitative leap in AI reasoning capabilities.
This release is seen as an important strategic turning point for Google in the AI competition. After being in a "red alert" state following the release of ChatGPT, Google is expected to reshape its market position through Gemini 3 Pro, especially in achieving breakthroughs in commercializing search AI models and enterprise AI scenarios.
Architectural Upgrades Drive Generational Performance Improvements
Gemini 3 Pro is built on a sparse mixture of experts transformer architecture, natively supporting multimodal inputs of text, images, audio, and video. This architecture dynamically routes input tokens to subsets of parameters through learning, decoupling the model's total capacity from the computational cost per token, significantly enhancing processing efficiency.
The model supports a context window of up to 1 million tokens, with an output capability of 64K tokens. The training data includes large-scale, multi-domain multimodal datasets, covering publicly available web documents, code, images, audio, and video content. The post-training phase employs reinforcement learning techniques, integrating multi-step reasoning, problem-solving, and theorem proving data.
According to the model card, Gemini 3 Pro is trained using Google TPU and employs the JAX and ML Pathways software frameworks. Data processing includes steps such as deduplication, safety filtering, and quality screening to enhance the reliability of training data and reduce risks.
Breakthrough Leadership in Multimodal Capabilities
In terms of multimodal processing capabilities, Gemini 3 Pro has established a significant advantage over competitors. In multimodal benchmark tests such as MMMU-Pro, ScreenSpot-Pro, and Video-MMMU, this model has shown a noticeable leap in performance compared to Gemini 2.5 Pro and generally surpasses GPT-5.1 and Claude 4.5 It is particularly noteworthy that in the screenshot understanding task, Gemini 3 Pro scored 72.7%, significantly surpassing the performance of other flagship models at 36.2%. In the Video-MMMU dimension, this model excelled in video information extraction and knowledge Q&A, continuing Google's traditional advantages in video understanding.
In the logical reasoning tests for image understanding, including benchmarks like Humanity's Last Exam, ARC-AGI-2, AIME 2025, and MathArena, Gemini 3 Pro greatly outperformed its predecessor as well as competitors like GPT-5.1 and Claude 4.5. Notably, in high-difficulty math lists such as AIME 2025, it achieved full marks in the "code execution" scenario, demonstrating its top-tier capabilities in tool invocation and mathematical reasoning.
Code and Agent Capabilities on Par with Competitors
In terms of code writing and agent applications, Gemini 3 Pro has shown strong overall strength. In "code + agent" benchmark tests such as LiveCodeBench Pro, SWE-Bench Verified, t2-bench, and Vending-Bench 2, the model's Elo scores and success rates are generally higher than those of older versions, and it is very close to GPT-5.1 in most dimensions.
However, in some specialized tests, the competitive landscape remains fierce. For example, in the SWE-Bench Verified test, Claude 4.5 still maintains a slight lead. This indicates that the AI industry is still in a "multiple strong contenders" pattern in real software engineering tasks, with no single model having a clear advantage.
In long text processing and information retrieval, Gemini 3 Pro has made significant improvements compared to 2.5 Pro. In long context and retrieval benchmarks like MRCR V2 and FACTS Benchmark Suite, this model can maintain a high accuracy rate even at a length of 128K. In the SimpleQA Verified test, its score exceeded 72%, significantly ahead of Claude Sonnet 4.5's 29% and GPT-5.1's 35%, showing a very low hallucination rate.
Security Assessment Passes Key Capability Threshold Tests
According to Google's DeepMind cutting-edge security framework assessment, Gemini 3 Pro did not reach key capability thresholds in several critical areas. In CBRN (Chemical, Biological, Radiological, Nuclear), cybersecurity, harmful manipulation, machine learning R&D, and misalignment risks, the model did not touch the alert thresholds.
In internal security assessments, Gemini 3 Pro showed overall improvements in text security, multilingual security, image text security, tone control, and inappropriate rejection compared to Gemini 2.5 Pro The artificial red team test confirms that the model meets the release requirements for children's safety assessment, with content safety policy performance comparable to or improved over previous products.
Google has implemented multiple safety mitigation measures during the model development process, including dataset filtering, conditional pre-training, supervised fine-tuning, and human feedback reinforcement learning. The main risks faced by the model include jailbreak attack vulnerabilities and potential performance degradation in multi-turn dialogues.
Commercial Prospects and Ecological Integration Advantages
Tianfeng Securities analyst Li Zeyu believes that although Gemini 3 Pro has not yet fully surpassed its competitors in coding capabilities, its significant lead in multimodal capabilities and text RAG capabilities, combined with Google's own search, Workspace, and Android ecosystems, is expected to greatly enhance market expansion capabilities in scenarios such as search AI model commercialization, document Q&A, and enterprise AI.
Gemini 3 Pro will be distributed through multiple channels, including the Gemini App, Google Cloud/Vertex AI, Google AI Studio, Gemini API, Google AI Mode, and Google Antigravity platforms. The model is particularly suitable for application scenarios that require agent performance, advanced coding, long context, multimodal understanding, and algorithm development.
Analysis suggests that the breakthrough in multimodal capabilities may give rise to a large number of emerging application scenarios, while Google's vast product ecosystem will provide ample space for the commercialization of these capabilities. Continued optimism for investment opportunities in Google and its industry chain-related beneficiaries
