
Xiaomi's latest large model achievement! Luo Fuli has appeared

小米 AI 团队与北京大学联合发布了一篇关于 MoE 与强化学习的论文,罗福莉作为通讯作者参与其中。论文提出了一种在 MoE 架构中提高大模型强化学习效率与稳定性的思路,解决了训练过程中的不稳定问题。该研究表明,强化学习在推动大模型能力突破方面至关重要,尤其是在预训练遇到瓶颈时。
小米的最新大模型科研成果,对外曝光了。
就在最近,小米 AI 团队携手北京大学联合发布了一篇聚焦 MoE 与强化学习的论文。

而其中,因为更早之前在 DeepSeek R1 爆火前转会小米的罗福莉,也赫然在列,还是通讯作者。
罗福莉硕士毕业于北京大学,这次也算是因 AI 串联起了小米和北大。
有意思的是,就在今年 9 月 DeepSeek 登上《Nature》的时候,罗福莉也出现在了作者名单,不过是以 “北京独立研究者” 的身份。

当时还有过风言风语,说当初 “雷军千万年薪挖来 AI 天才少女”,当事人可能离职了。
但这篇小米最新 AI 论文披露后,一切似乎有了答案…
小米最新 AI 成果:找到 RL 中稳定和效率的平衡
这篇论文大道至简,提出了一种在 MoE 架构中提高大模型强化学习的思路。
相对已经共识的是,当前强化学习已成为在预训练遇到瓶颈后,推动 LLM 突破能力边界的关键工具。
不过在 MoE 架构中,情况就没那么简单了,由于需要根据问题分配不同的专家,路由机制会让训练过程变得不稳定,严重时甚至会直接把模型 “整崩”。
为了解决这个问题,研究团队提出了一种全新的思路,让 MoE 也能平稳且高效地推进大规模强化学习。
强化学习的灾难性崩溃
自从预训练时代告一段落,后训练成了巨头们拿起 Scaling Law 瞄准的的下一个战场。
靠着大规模强化学习,大模型开始学会更长链路的推理,也能搞定那些需要调用工具的复杂 Agent 任务。
不过,强化学习在扩展规模的过程中,总会不可避免地撞上一道铁幕:效率和稳定性的权衡。
想要高效率,就得训练得更 “猛”——更高的学习率、更大的并行度、更频繁的样本更新。可这样一来,稳定性也更容易出现问题。
但一味追求稳定也不行,效率会被拖住,模型训练慢得像蜗牛。
想要解决这个问题,得先回到强化学习的底层一探究竟。
LLM 的强化学习,通常分两步:
第一步是推理,模型自己生成内容、和环境互动、拿到反馈分数;
第二步是训练,根据这些分数去微调自己,并想办法在下次拿更高分。
不过,这两步通常不是在同一套系统里跑的。
比如,现在主流方案是SGLang负责生成内容,追求速度快;而Megatron负责训练更新,追求算得准。
虽然两边用的是同一套模型参数,但底层实现有细微差别,比如像随机性、精度、并行方式、缓存策略,这些看似微不足道的细节波动,都会让结果出现偏差。
于是就出现了一个尴尬现象:
一模一样的 Prompt,两套模式下最终生成的结果都能不一样。
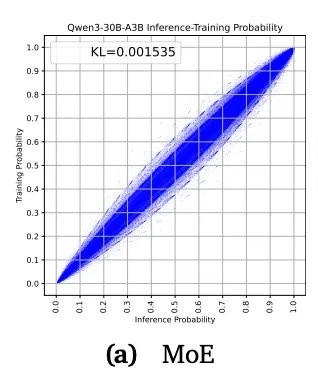
这种「概率漂移」积累多了,模型就会越学越偏,最后学着学着,训练目标和实际表现彻底牛头不对马嘴。
这就是业内常说,强化学习灾难性崩溃。
路由重放机制
研究团队指出,导致 MoE 在强化学习中容易崩掉的罪魁祸首,在于路由分布。
在 MoE 模型中,路由器不会把所有参数都用上,而是会根据每个输入 token 的特征,挑几位在该领域更擅长的 “专家” 出来干活,从而可以节省不少资源。
但副作用也很明显,这种动态模式会让模型在训练阶段和推理阶段得出的最佳策略大相径庭,比传统的稠密模型要 “飘忽” 得多。
对此,这篇论文给出了一种新颖的解决方案。
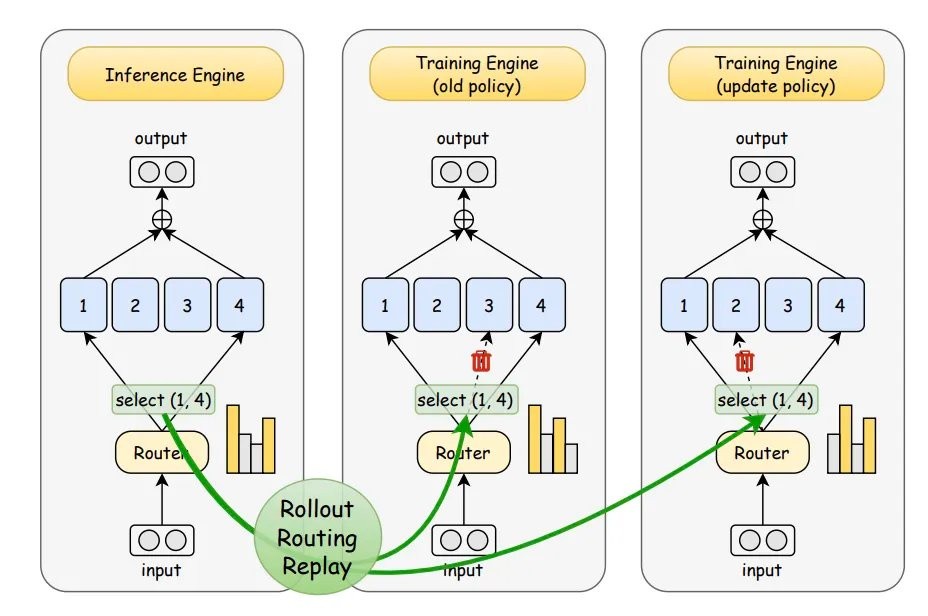
既然问题出在路由随机,那为何不直接把路由锁住呢?
他们的做法是:在推理时把路由分布记录下来,等到训练时再把这些分布原封不动地 “重放” 进去。
这样,训练和推理就走同一条路线,不再各干各的。
根据这种 “重放” 的特定,研究将这种方法命名为——Rollout Routing Replay(R3)。
解决了稳定性的问题,再来看看如何把效率也稳稳拿下。
在强化学习中,模型会不断重复“生成→获得奖励→更新→再生成”的飞轮,一个完整过程下来,可能要跑上几十万、甚至上百万次推理。
要是每次生成都要从头计算上下文,算力与时间成本将呈几何式增长。
为应对这种情况,主流推理引擎普遍采用KVCache 前缀缓存策略:把之前算好的上下文保存下来,下次直接 “接着算”。
不过,除了上下文不一致,MoE 架构还涉及到路由选择不一致的问题——按照传统的解决方案,即便是重复的上下文,每一次计算,模型还是要重新选专家、激活专家。
因此,研究团队在 KVCache 的基础上又加了一招——路由掩码(routing mask)。
他们的想法是,既然对于对相同的上下文,MoE 的路由结果应该一样,那干脆,把推理阶段的路由掩码和前缀 KVCache 一起缓存起来。
这样当相同上下文再次出现时,模型就能直接用上次的掩码,不必重算。
这样,R3 就能够与现有的前缀缓存系统无缝衔接,在大规模强化学习及复杂的 Agent 任务中,也依然能保持出色的计算效率。
实验结果
为评估 R3 的实际效果,研究团队基于Qwen3-30B-A3B模型进行了一系列实验。
总体性能:
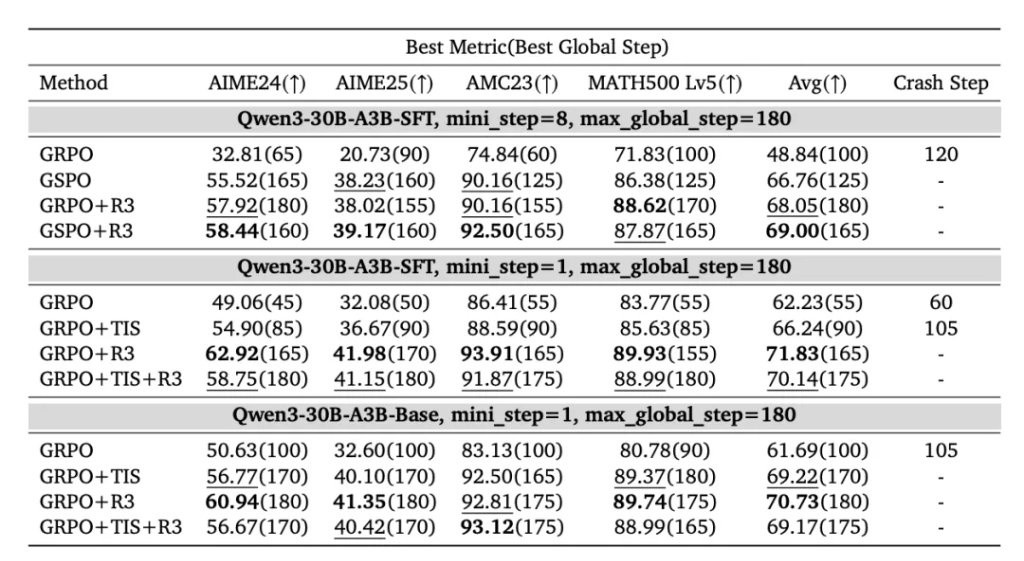
结果发现,不管在哪种场景下,R3 的整体成绩都更好。
在多 mini-step 设置下,GRPO+R3 的表现比 GSPO 高出1.29 分。
若将 R3 与 GSPO 结合,性能还可以进一步提升0.95 分。
训练稳定性:
崩溃情况也少了很多。
不难看出,随着训练时间的延长,即便到了第 150 步,R3 依然能保持相对平缓的曲线。
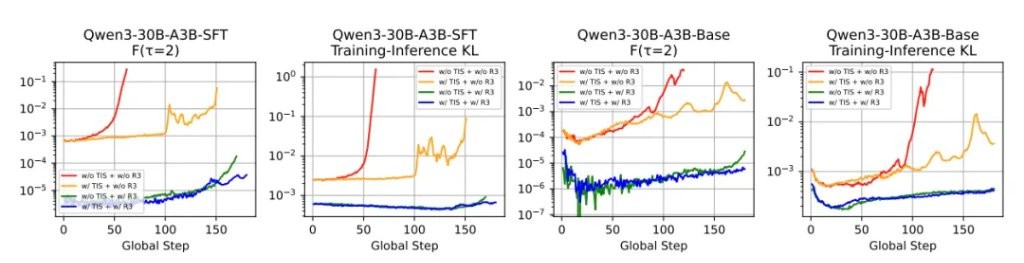
相比之下,如果是用 GRPO 训练,到第 60 步时就已经严重跑偏。
优化与生成行为:
而且,R3 不光让模型更稳,也让它更聪明。
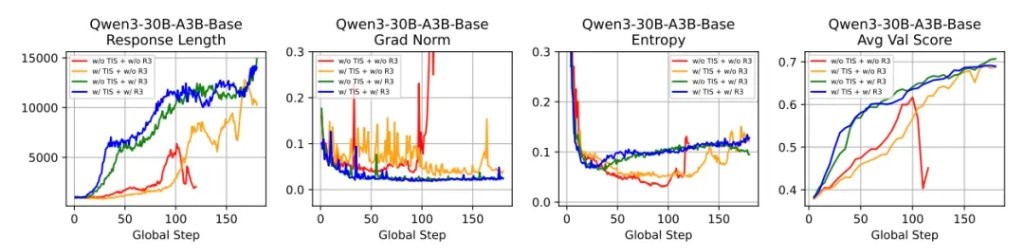
实验结果结果表明,R3 能更快找到正确方向、优化过程更丝滑,还能更早开始探索更优策略。
一句话总结,研究团队在这篇论文提出了一种叫 R3 的方法,通过在训练中复用推理阶段的路由分布,能够让MoE 模型的强化学习更稳定、更高效。
论文作者
说完论文,再让我们看看这支由小米系和北京大学携手牵起的研究团队。
论文的第一作者叫Wenhan Ma。
资料不多,只知道 Wenhan 是小米 LLM-Core 团队的研究员,而且还是实习生。
此前,他还曾参与过小米 MiMo 模型与多模态 MiMo-VL 的研发。

相比起来,这篇论文的两名通讯作者,大家可能更耳熟能详一点。
一位是罗福莉。

罗福莉本科毕业于北京师范大学计算机专业,硕士阶段进入北京大学计算语言学深造。期间,她在不少 NLP 顶级会议上都发表过论文。
硕士毕业后,罗福莉加入阿里巴巴达摩院,担任机器智能实验室研究员,负责开发多语言预训练模型VECO,并推动AliceMind项目的开源工作。
2022 年,罗福莉加入 DeepSeek 母公司幻方量化从事深度学习相关工作,后又担任 DeepSeek 的深度学习研究员,参与研发 DeepSeek-V2 等模型。
截至目前,罗福莉的学术论文总引用次数已超过 1.1 万次,仅在今年一年内就新增了约八千次引用。
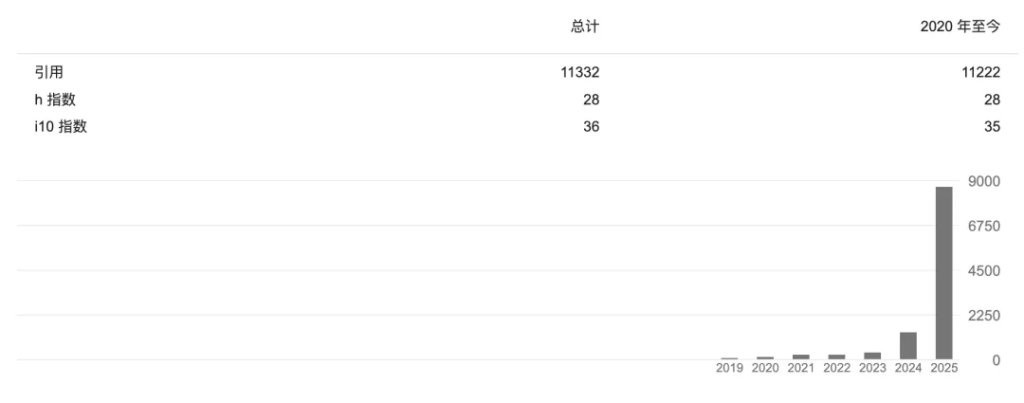
而另一名通讯作者,正是罗福莉的北大硕士导师——穗志方。

穗教授是北京大学信息科学技术学院的教授、博士生导师,长期从事计算语言学、文本挖掘与知识工程研究,在 NLP 与 AI 领域发表了大量高水平论文。
但稍有有个新问题,在这篇论文成果的单位注释中,罗福莉的单位没有被明确,她既不是北大的,也没有被归入小米。

咦……依然是独立研究者?
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
