
AI Expert: Doubts about AI are "self-deception" regarding the "exponential growth trend"

AI 研究員 Julian Schrittwieser 認為,當前的 “AI 泡沫論”,是未能理解技術指數級增長趨勢的表現,與新冠疫情初期的誤判類似。研究顯示,AI 在軟件工程、跨行業職業任務等領域的性能正呈指數級增長,並預測到 2026 年中,AI 將能自主完成 8 小時工作,並在年底前在多個行業達到人類專家水平。
一位來自 AI 研究前沿的專家堅定反駁了當前普遍存在的 “AI 泡沫論”。
AI 明星公司 Anthropic 的研究員 Julian Schrittwieser 在其個人博客中撰文警告,當前對 AI“泡沫” 或 “平台期” 的普遍質疑,是對技術指數級增長趨勢的嚴重誤讀,這種心態與新冠疫情初期對指數級傳播的忽視如出一轍。
當前圍繞 AI 進步和所謂 “泡沫” 的討論,讓我想起了新冠疫情的最初幾周。當指數趨勢已經清晰預示了全球大流行的到來及其規模時,政客、記者和大多數公眾評論員卻仍將其視為一種遙遠的可能性或局部現象。
他指出,儘管 AI 在執行編程或網站設計等任務時仍會犯錯,但人們因此斷言其無法達到人類水平或影響甚微是 “一種奇怪的現象”,正如幾年前人們還認為 AI 編程是 “科幻小説”。
人們注意到,雖然 AI 現在可以編寫程序、設計網站等,但它仍然經常犯錯或走向錯誤的方向,然後他們不知何故就得出結論,認為 AI 永遠無法在人類水平上完成這些任務,或者只會產生微小的影響。
Schrittwieser 的核心論點基於兩項關鍵研究:METR 和 OpenAI 的 GDPval。數據顯示,AI 模型自主完成複雜任務的時長正以指數級速度翻倍,最新的模型已能處理超過兩小時的軟件工程任務。更重要的是,在覆蓋 44 個職業的 GDPval 評估中,頂尖 AI 的表現已 “驚人地接近” 人類水平,甚至開始挑戰行業專家的能力。
在這篇題為《再次未能理解指數級》的博客文章中,Schrittwieser 將當前對 AI 的懷疑論調比作 “自欺欺人”,認為人們因關注當下的不完美而低估了即將到來的變革規模。

軟件任務能力:每 7 個月翻一番
為反駁 AI“平台期” 論調,Schrittwieser 首先引用了獨立評估機構 METR 發佈的《衡量 AI 完成長任務的能力》研究。該研究衡量 AI 模型能自主執行軟件工程任務的長度,結果顯示出 “清晰的指數級趨勢”。
根據該研究,7 個月前的模型 Sonnet 3.7 已能以 50% 的成功率完成長達一小時的任務。而 METR 網站上的最新圖表則進一步證實了這一趨勢的延續性。
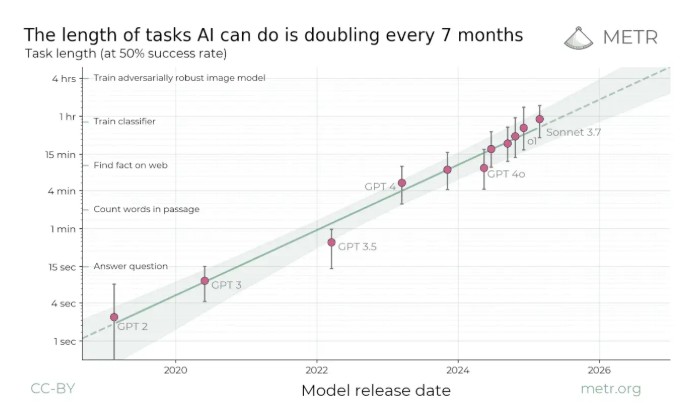
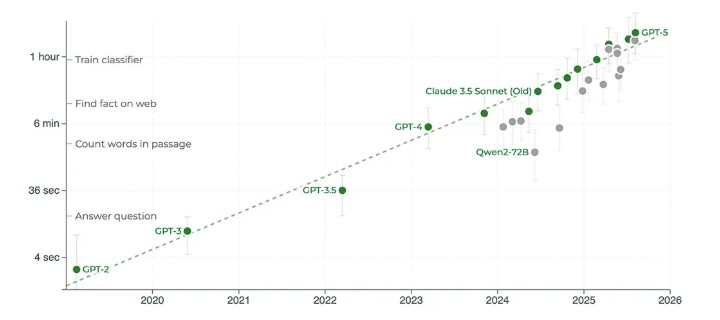
Schrittwieser 指出,包括 Grok 4、Opus 4.1 和 GPT-5 在內的新模型不僅延續了趨勢,“這些最新模型實際上略高於趨勢,現在能執行超過 2 小時的任務!”
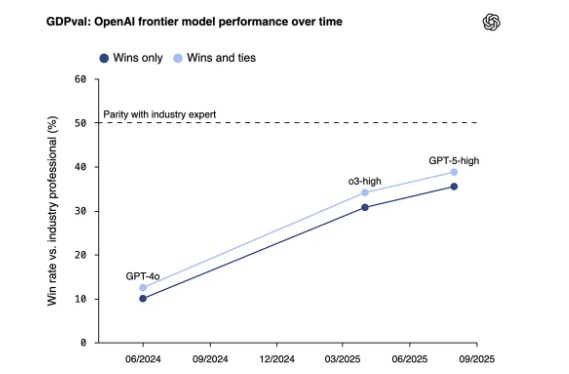
跨越代碼:在 44 個職業中追趕人類專家
針對 “AI 僅在軟件工程領域表現出色” 的質疑,Schrittwieser 引用了 OpenAI 發佈的另一項名為 GDPval 的評估。該研究旨在衡量模型在更廣泛經濟活動中的表現,涵蓋了 9 個行業的 44 個職業,任務由平均擁有 14 年經驗的行業專家提供。
結果再次呈現相似趨勢。Schrittwieser 寫道,最新的 GPT-5 已 “驚人地接近人類表現”。
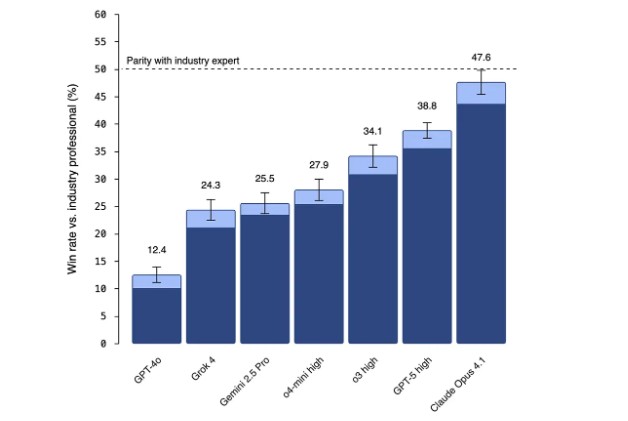
更有説服力的是,早於 GPT-5 發佈的 Claude Opus 4.1 在該項評估中表現更佳,其性能 “幾乎與行業專家的表現相匹配”。Schrittwieser 特別對此評論:“我在這裏要特別讚揚 OpenAI 發佈了一項評估,顯示了另一家實驗室的模型超越了他們自己的模型——這是誠信和關心有益 AI 成果的好跡象!”
展望 2026:AI 經濟整合的 “關鍵一年”
基於上述跨越多年和多個行業的指數級增長數據,Schrittwieser 認為,若這些改進突然停止將是 “極其令人驚訝的”。他給出了一個基於趨勢外推的清晰預測:
- 到 2026 年中,模型將能夠自主工作一整個工作日(8 小時)。
- 到 2026 年底,至少有一個模型將在許多行業中達到人類專家的表現水平。
- 到 2027 年底,模型在許多任務上將頻繁超越專家。
他總結道,未來的模型可能會比專家更好。
這聽起來可能過於簡單,但通過推斷圖表上的直線進行預測可能會給你一個比大多數 “專家” 更好的未來模型——甚至比大多數實際領域專家更好!
