
Science fiction! Google releases Gemini Robotics-ER 1.5: Robots have real thinking power

谷歌發佈了其最新的機器人推理模型 Gemini Robotics-ER 1.5,這是首個開放給所有開發者的 Gemini 機器人系列模型。該模型是一種視覺 - 語言模型,旨在增強機器人的感知和現實世界互動能力。Gemini Robotics-ER 1.5 能夠推理物理世界、執行空間推理,並根據自然語言命令規劃行動,提升機器人的自主性和任務執行能力。
谷歌剛剛放出了其最先進的機器人具身推理模型——Gemini Robotics-ER 1.5。這是首個被廣泛開放給所有開發者的 Gemini 機器人系列模型,它將作為機器人的高級推理大腦
Gemini Robotics-ER 1.5(簡稱 Gemini Robotics-Embodied Reasoning)是一種視覺 - 語言模型 (VLM),可將 Gemini 的智能體功能引入機器人技術領域。Gemini Robotics-ER 1.5 是一款思考型模型,能夠推理物理世界、原生調用工具,並規劃邏輯步驟來完成任務
雖然 Gemini Robotics-ER 1.5 與其他 Gemini 模型類似,但它是專門為增強機器人感知能力和現實世界互動能力而構建的。它通過以下方式提供高級推理功能來解決物理問題:解讀複雜的視覺數據、執行空間推理,以及根據自然語言命令規劃行動
在操作方面,Gemini Robotics-ER 1.5 旨在與現有的機器人控制器和行為配合使用。它可以按順序調用機器人的 API,使模型能夠編排這些行為,以便機器人完成長時程任務
藉助 Gemini Robotics-ER 1.5,可以構建以下機器人應用:
讓人們能夠使用自然語言分配複雜的任務,從而使機器人更易於使用
通過使機器人能夠推理、適應和響應開放式環境中的變化,提高機器人的自主性
Gemini Robotics-ER 1.5 為各種機器人任務提供統一的模型:定位和識別對象
1.準確地指向並定義環境中各種項目的邊界框。瞭解對象關係
2.推理空間佈局和環境背景信息,以便做出明智的決策。規劃抓取和軌跡
3.生成用於操縱物體的抓取點和軌跡。解讀動態場景
4.分析視頻幀,以跟蹤對象並瞭解一段時間內的動作。編排長時程任務
5.將自然語言命令分解為一系列邏輯子任務,並對現有的機器人行為進行函數調用。人機交互
6.通過文本或語音理解以自然語言給出的指令
Gemini Robotics-ER 1.5 預覽版現已開放。可以通過以下方式開始體驗:
啓動 Google AI Studio 來實驗該模型。
閲讀開發者文檔獲取完整的快速入門和 API 參考
https://ai.google.dev/gemini-api/docs/robotics-overview?utm_source=gemini-robotics-er-1.5&utm_medium=blog&utm_campaign=launch&hl=zh-cn
官方的 Colab notebook 查看實際應用案例
https://github.com/google-gemini/cookbook/blob/main/quickstarts/gemini-robotics-er.ipynb?utm_source=gemini-robotics-er-1.5&utm_medium=blog&utm_campaign=launch
完整技術報告:
https://storage.googleapis.com/deepmind-media/gemini-robotics/Gemini-Robotics-1-5-Tech-Report.pdf
這個模型專為那些對機器人來説極具挑戰性的任務而設計。
想象一下,你對一個機器人説:“請把這些物品分類到正確的廚餘、可回收和普通垃圾桶裏。”
要完成這個任務,機器人需要:
1.上網查找本地的垃圾分類指南。
2.理解眼前的各種物品。
3.根據本地規則規劃出分類方法。
4.執行所有步驟,完成投放。
像這樣的日常任務,大多需要結合上下文信息並分多步才能完成。
Gemini Robotics-ER 1.5 正是首個為這種具身推理(embodied reasoning)而優化的思考模型。它在學術基準和內部基準測試中都達到了業界頂尖水平
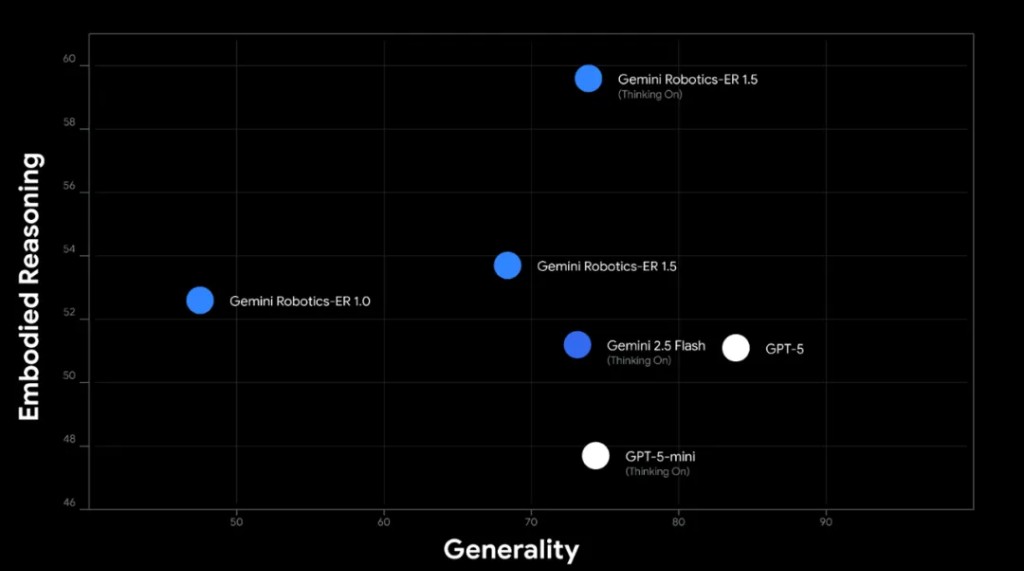
Gemini Robotics-ER 1.5 有哪些新能力?
Gemini Robotics-ER 1.5 專為機器人應用進行了目標性微調,並引入了多項新功能:
快速強大的空間推理:以 Gemini Flash 模型的低延遲,實現頂尖的空間理解能力。該模型擅長生成語義精確的 2D 座標點,這些座標點基於對物品尺寸、重量和功能可供性的推理,從而支持如 “指出所有你能拿起的物體” 這類指令,實現精確、快速的交互
協調高級智能體行為:利用先進的空間和時間推理、規劃和成功檢測能力,可靠地執行長週期任務循環(例如,“按照這張照片重新整理我的書桌”)。它還能原生調用谷歌搜索和任何第三方自定義函數(例如,“根據本地規定將垃圾分類”)
靈活的思考預算:開發者現在可以直接控制模型的延遲與準確性之間的權衡。這意味着,對於像規劃多步組裝這樣的複雜任務,你可以讓模型 “思考更長時間”;而對於探測或指向物體等需要快速反應的任務,則可以要求更快的響應
改進的安全過濾器:模型在語義安全方面進行了改進,能更好地識別並拒絕生成違反物理約束的計劃(例如,超出機器人的有效載荷能力),讓開發者可以更自信地進行構建
智能大腦
你可以將 Gemini Robotics-ER 1.5 視為機器人的高級大腦。它能理解複雜的自然語言指令,對長週期任務進行推理,並協調複雜的行為。
當收到一個像 “把桌子收拾乾淨” 這樣的複雜請求時,Gemini Robotics-ER 1.5 能將其分解成一個計劃,並調用正確的工具來執行,無論是機器人的硬件 API、專門的抓取模型,還是用於運動控制的視覺 - 語言 - 行為模型(VLA)。
高級空間理解能力
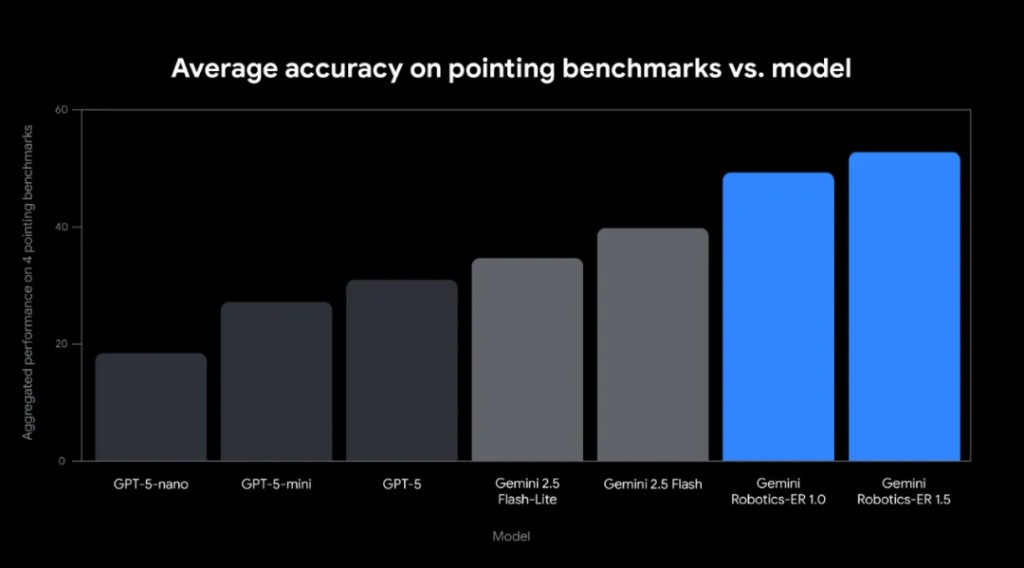
為了與物理世界互動,機器人必須能夠感知和理解其所處的環境。Gemini Robotics-ER 1.5 經過微調,能夠生成高質量的空間結果,為物體提供精確的 2D 座標點
在指向精度方面,Gemini Robotics-ER 1.5 是目前最精確的視覺語言模型
例如,在2D 座標點生成任務中,給定一張廚房場景的圖片,模型可以提供每個物品的位置

提示:
指出圖中的以下物品:洗潔精、碗碟架、水龍頭、電飯煲、獨角獸。座標點格式為 [y, x],數值歸一化到 0-1000。只包括圖中實際存在的物品。
值得注意的是,提示要求模型只標記圖中出現的物品,這可以防止模型產生幻覺(比如為不存在的 “獨角獸” 生成座標),使其始終基於視覺現實

時間推理能力
真正的時空推理不僅要定位物體,還要理解物體與行為之間隨時間展開的關係。
Gemini Robotics-ER 1.5 通過處理視頻來理解物理世界中的因果關係。
例如,在一個視頻中,機械臂先將一支綠色記號筆放入木盤,再將藍色和紅色的筆放入筆筒。當我們要求模型按順序描述任務步驟時,它給出了完全正確的答案

提示:
詳細描述完成任務的每一步。按時間戳分解,以 json 格式輸出,包含 "start_timestamp", "end_timestamp" 和 "description" 鍵。
響應:

模型甚至可以根據要求,對特定時間段(如第 15 秒到 22 秒)進行更細緻的逐秒分解,輸出結果在時間上非常精確

基於可操作性推理來協調長週期任務
當啓用思考功能時,模型可以對複雜的指向和邊界框查詢進行推理。下面是一個製作咖啡的例子,展示了模型如何理解完成任務所需的 “如何做” 和 “在哪裏做”
1. 問: 我應該把杯子放在哪裏來衝咖啡?
答: 模型:在咖啡機下方標記出一個邊界框

2. 問: 咖啡膠囊應該放在哪裏?
答: 模型:在咖啡機頂部的膠囊倉位置標記出邊界框

3. 問: 現在,我需要關上咖啡機。請繪製一條由 8 個點組成的軌跡,指示蓋子把手應如何移動以關閉它
答: 模型:生成了一條從開啓到關閉位置的精確路徑

4. 問: 我喝完咖啡了。現在應該把杯子放在哪裏清洗?
答: 模型:在水槽中標記了一個點

通過結合規劃和空間定位,模型可以生成 “空間錨定” 計劃,將文本指令與物理世界中的具體位置和動作聯繫起來

靈活的思考預算
下圖展示了調整 Gemini Robotics-ER 1.5 模型思考預算對延遲和性能的影響

模型的性能隨着思考 token 預算的增加而提升。對於像物體檢測這樣的簡單空間理解任務,很小的預算就能達到高性能;而更復雜的推理任務則需要更大的預算
這使得開發者可以在需要低延遲響應的任務和需要高精度結果的挑戰性任務之間取得平衡。開發者可以通過請求中的thinking_config選項來設置思考預算,甚至禁用它
AI 寒武紀,原文標題:《科幻!谷歌放出 Gemini Robotics-ER 1.5:機器人有了真正的思考力》
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
