
Alibaba releases 3 large models at once: the multimodal Qwen3-Omni, the image editing large model Qwen-Image-Edit-2509, and Qwen3-TTS

Alibaba recently released three large models, including the open-source multimodal large model Qwen3-Omni, the image editing large model Qwen3-Image-Edit, and the speech recognition large model Qwen3-TTS. Qwen3-Omini-30B-A3B is a multimodal model capable of processing text, images, speech, and video, with a parameter scale of 30 billion, supporting free commercial use. Compared to previous versions, this model has excelled in multiple speech and multimodal tasks, achieving 22 first-place rankings
A few hours ago, Alibaba updated three large models at once, namely the open-source multimodal large model Qwen3-Omni, the open-source image editing large model Qwen3-Image-Edit, and the non-open-source speech recognition large model Qwen3-TTS. The three models released this time are all multimodal large models, which can be said that Alibaba's large models are truly flourishing and the pace is very fast!

Free Commercial Use Multimodal Large Model: Qwen3-Omini-30B-A3B
Qwen3-Omini-30B-A3B is Alibaba's open-source multimodal large model. The so-called multimodal means that this model can handle four different types of data: text, images, speech, and video, and can return either text or speech.
Alibaba's previous version of the multimodal large model, Qwen2.5-Omni, was released six months ago and is a dense model with 7 billion parameters. The open-sourced model this time is a multimodal large model based on the MoE architecture, with a total of 30 billion parameters, activating 3 billion during each inference.
According to Junyang Lin, the head of the Alibaba Qwen team, this year, Alibaba's speech team invested heavily in building a large-scale high-quality speech dataset, thereby improving the quality of Alibaba's ASR and TTS models. Then, Alibaba combined these capabilities to form this multimodal large model. This model is built on the Qwen3 model upgraded by Alibaba in July and is available in both non-inference and inference mode versions.
According to Alibaba's official introduction, compared to Qwen2.5-Omni, GPT-4o, and Gemini-2.5-Flash, Qwen3-Omini-30B-A3B achieved 22 first-place rankings in 36 speech and audio-visual multimodal tasks, which is quite impressive!

It is worth noting that this model is completely open-source, with an open-source license of Apache 2.0, allowing free commercial use. The open-source address and online demo address can be referenced at DataLearnerAI's Qwen3-Omini-30B-A3B model information card: https://www.datalearner.com/ai-models/pretrained-models/Qwen3-Omni-30B-A3B
The First Open-Source Image Editing Large Model Qwen-Image-Edit-2509
Alibaba's other large model that has been open-sourced this time is the image editing large model Qwen-Image-Edit-2509. As can be seen from the name, this is an upgraded version of the image editing large model.
In fact, Alibaba just open-sourced the Qwen-Image-Edit version last month. This version has already achieved first place in the open-source field on the large model anonymous arena. Just a month later, Alibaba has open-sourced this upgraded version of the model, which is quite agile!
In simple terms, the upgrades in Qwen-Image-Edit-2509 mainly consist of three major aspects:
- You can now work with multiple images! Previously, it mainly handled single images, but the new version has learned the "collage" technique. You can throw several images at it for processing. For example, you can combine two people into one image or place a person next to a product, offering more ways to play.
- The effect of editing a single image is now more realistic and consistent! This is a significant improvement, especially in:
- Portrait editing is more stable. Now when changing a person's style or look, the face is less likely to distort, maintaining the feeling of "this is the same person."
- Product editing is more accurate. When modifying product posters, the appearance of the product itself is better preserved and does not become unrecognizable.
- Text editing is stronger. Not only can you change the text content, but you can also modify the font, color, and texture (for example, making it look like metallic text).
- Comes with a "control switch" (ControlNet): This is a boon for those in the know! It now natively supports using depth maps, line drawings, and skeletal point maps as "guiding images" to precisely control the generation effects, eliminating the need for extra adjustments, making the output more controllable.
In summary, it has stronger functionality, more natural effects, and higher controllability! In the evaluation comparison of the Image Edit Arena in the large model anonymous arena, the Qwen-Image-Edit from August was voted first among global open-source models, and this upgraded Qwen-Image-Edit-2509 should also perform even better!
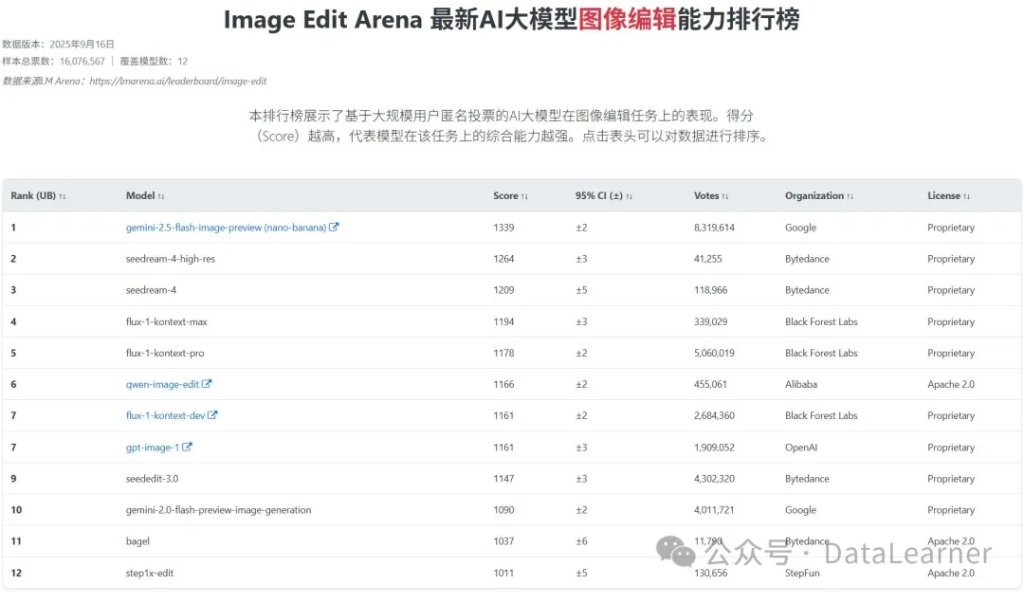
Data source: https://www.datalearner.com/leaderboards/category/image-edit
Most importantly, this model is also under a free commercial use open-source license. The specific open-source address and online experience address can also be referenced in the DataLearnerAI large model information card: https://www.datalearner.com/ai-models/pretrained-models/Qwen-Image-Edit-2509
Non-open-source but Very Affordable Speech Recognition Large Model Qwen3-TTS-Flash
In addition to the two open-source models mentioned above, Alibaba has also released a paid model Qwen3-TTS-Flash.
As mentioned earlier, this year Alibaba's speech team invested heavily in building a high-quality speech dataset, with the most important output being large models for speech recognition and speech synthesis. On September 8, 2025, Alibaba released the Qwen3-ASR model, which has a speech recognition error rate lower than GPT-4o and Gemini 2.5 Pro! It is also a non-open-source model.
This time, Alibaba has once again released the speech synthesis model Qwen3-TTS-Flash, which is characterized by its ability to speak with emotion, making the voice sound more like a real person. In professional speech synthesis stability tests, its results have surpassed well-known competitors such as SeedTTS, MiniMax, and even GPT-4o-Audio-Preview, reaching the best level currently available.
Additionally, Qwen3-TTS-Flash supports 17 different voices, each supporting 10 different languages, including Chinese, English, Korean, German, Italian, Spanish, French, Russian, and more. It also supports many dialects of Chinese and English, including Cantonese, Sichuan dialect, American accent, British accent, etc.
Qwen3-TTS-Flash is not open-source, and the API price is 0.8 RMB for 10,000 characters, with a maximum input support of 600 characters (the official introduction currently only provides pricing in Chinese, and this character count may refer to tokens).
Further information on Qwen3-TTS-Flash can be found in the DataLearnerAI model information card: https://www.datalearner.com/ai-models/pretrained-models/Qwen3-TTS-Flash
Summary
Overall, Alibaba has released three multimodal models at once, which reveals a clear strategic approach: on one hand, they are building an ecosystem through open-source multimodal and image editing models to engage developers and the community; on the other hand, they are directly commercializing with a closed-source but low-cost speech synthesis model, forming a parallel strategy of "open-source for momentum, closed-source for cashing in."
The quality of Alibaba's open-source models is very high, earning a good reputation. Currently, their pace is also very fast, with a large number of new models appearing every month, making it very worthy of attention. In many niche areas, their open-source models have achieved very good results.
Risk Warning and Disclaimer
The market has risks, and investment requires caution. This article does not constitute personal investment advice and does not take into account individual users' specific investment goals, financial situations, or needs. Users should consider whether any opinions, views, or conclusions in this article align with their specific circumstances. Investing based on this is at one's own risk
