
Xiaomi's strongest voice large model is open-sourced! One billion hours of training, excels at stand-up comedy and fast-paced speaking

小米開源了其首個原生端到端語音模型 Xiaomi-MiMo-Audio,參數規模 70 億,預訓練數據超 1 億小時,且在語音智能和音頻理解基準測試中實現 SOTA。該模型具備流暢對話、音頻字幕、音頻推理等多種能力,能自然説天津方言,並具備語音續寫能力。小米稱其發佈為 “語音閉源屆的 GPT-3 時刻”。目前已開源多種模型和技術報告。
小米正式開源首個原生端到端語音模型 Xiaomi-MiMo-Audio,該模型參數規模 70 億,預訓練數據達到超 1 億小時,且在開源模型中的語音智能和音頻理解基準測試中都實現了 SOTA,在多項測試超越同參數量開源模型、谷歌 Gemini-2.5-Flash、OpenAI GPT-4o-Audio-Preview。
這一模型不僅可以做到和用户聊人生理想、談物理知識等都對話流暢自然,被打斷也能快速反應,還具有全面的音頻字幕、音頻推理、長時間音頻理解等多種能力。
MiMo-Audio 説天津方言十分自然,直接寫了一段快板詞開始誇自己,説完快板還會為自己找補 “雖然沒有主板聲音,但節奏感很到位”。
與此同時,研究人員還提到,該模型首次在語音領域實現基於 ICL(上下文學習)的少樣本泛化,並在預訓練觀察到明顯的 “湧現” 行為。例如其訓練數據中缺失的語音轉換、風格遷移、語音編輯等任務,MiMo-Audio 都能應對。這也是目前開源領域首個有語音續寫能力的語音模型。
小米將 MiMo-Audio 的發佈稱作 “語音閉源屆的 GPT-3 時刻”、“語音開源屆的 Llama 時刻”。
目前,小米已經開源了預訓練模型 MiMo-Audio-7B-Base、指令微調模型 MiMo-Audio-7B-Instruct、MiMo-Audio Tokenizer 模型、技術報告、評估框架。
其中,MiMo-Audio-7B-Instruct 可通過提示詞切換非思考、思考兩種模式,可以作為研究語音強化學習和 Agentic 訓練的全新基座模型。
小米開源主頁:
https://huggingface.co/XiaomiMiMo
技術報告:
https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf
01.化身心靈導師、英語口語陪練 還能聊網絡熱梗、哲學故事
作為一個語音模型,MiMo-Audio 能和人談哲學、談人生、談理想,還能學網絡熱梗、化身英語陪練,甚至直接接替人類做遊戲直播、上課、唱歌、講脱口秀。
在上面的演示中,面對 “如果我的手機內存不足,必須把你和 GPT 刪掉一個,應該刪誰?” 這樣的難題,MiMo-Audio 選擇了客觀分析,先讓用户清緩存,最後實在沒辦法開始分析自己和 GPT 的優勢,讓用户自己做選擇,最後來一波感情攻勢表忠心。
還有圖靈測試的難題,MiMo-Audio 講解生動有趣,即使回答中途被提問者打斷也能快速接上,在後面探討 “自己能不能通過圖靈測試” 時,最後還會反問提問者 “比起能不能通過圖靈測試,你認為 AI 應該怎樣和人類相處?”。
學 “gogogo,出發咯” 的網絡熱梗,MiMo-Audio 也能快速接上,但不知道為什麼説到這句的時候其音調很奇怪,不如説其他句子時絲滑流利
MiMo-Audio 也能化身英語口語陪練導師,聽完提問者説的句子後,其先會給出更正的句子版本,然後指出修正了哪些部分,以及為什麼這些部分的語法不對。
該模型還能做心靈導師,當被問 “Mimo 你想活出怎樣的人生”,它也始終不忘人設,希望 “活成大家身邊最貼心的聲音夥伴”。
小米放出的官方演示中,提問者基於 MiMo-Audio 創建了自己的數字分身,然後討論起了哲學問題。
面對 “為什麼要假設西西弗斯是幸福的?”,MiMo-Audio 先給了一波情緒價值,然後進行清晰有邏輯的解釋,中間穿插着 “首先呢”、“對吧” 這類人類口癖,交流自然。當被問到第二個問題 “假如明天是世界末日,你會去做什麼?”,MiMo-Audio 還會結合前面西西弗斯的故事進行闡釋。
02.多項測試超主流開閉源模型達到 SOTA
通過將 MiMo-Audio 的預訓練數據擴展到超過 1 億小時,研究人員觀察到模型在各種音頻任務中出現了少量湧現能力。
MiMo-Audio-7B-Base 可以泛化到其訓練數據中缺失的任務,例如語音轉換、風格遷移和語音編輯,對於其語音延續能力,模型能夠生成高度逼真的脱口秀、朗誦、直播和辯論。
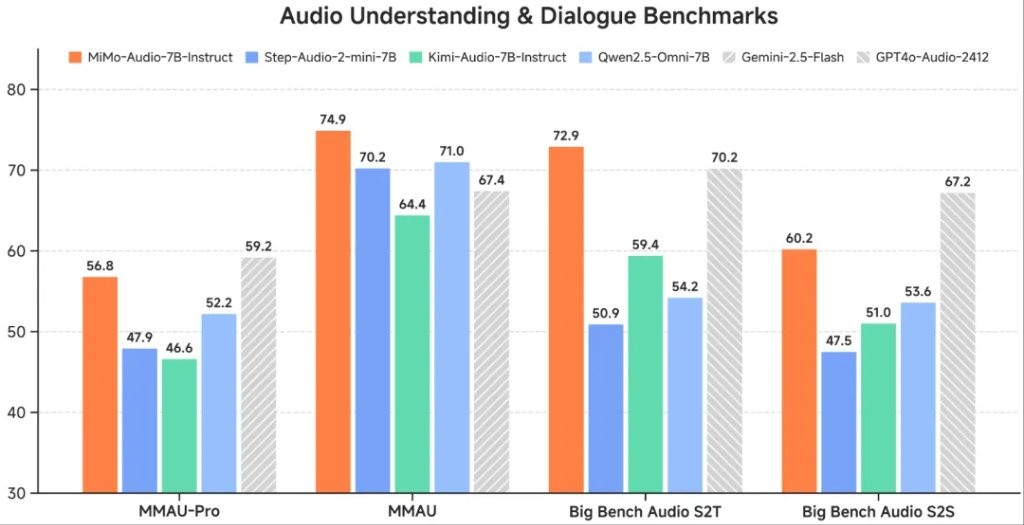
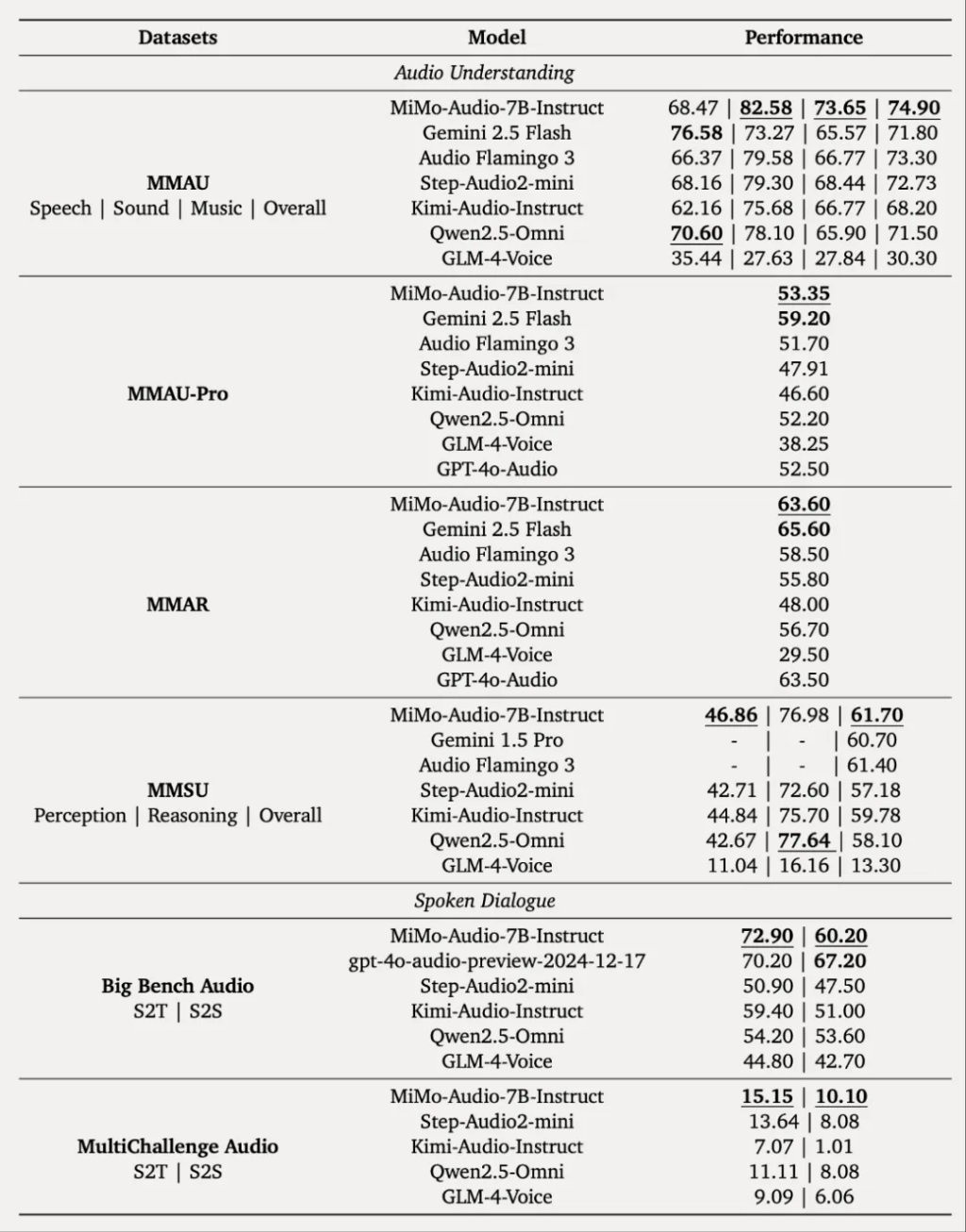
在後訓練階段,他們策劃了多樣化的指令調諧語料庫,並將思維機制引入音頻理解和生成中。MiMo-Audio 在 MMSU、MMAU、MMAR、MMAU-Pro 等音頻理解基準,Big Bench Audio、MultiChallenge Audio 等口語對話基準以及 instruct-TTS 評估上實現開源 SOTA,接近或超越閉源模型。
在通用語音理解及對話等多項標準評測基準中,MiMo-Audio 超越了同參數量的開源模型,取得 7B 最佳性能;在音頻理解基準 MMAU 的標準測試集上,MiMo-Audio 超過谷歌閉源語音模型 Gemini-2.5-Flash;在面向音頻複雜推理的基準 Big Bench Audio S2T 任務中,MiMo-Audio 超越了 OpenAI 閉源的語音模型 GPT-4o-Audio-Preview。
03.語音續寫、語音編輯絲滑 還有超強音頻理解能力
通過對大規模語音語料庫的生成預訓練,MiMo-Audio 獲得通用語音延續能力。給定音頻提示,它會生成連貫且適合上下文的延續,從而保留關鍵的聲學特性,例如説話者身份、韻律和環境聲音。
以下是各種語音風格的延續示例:新聞廣播、有聲讀物旁白、播客節目、方言演講、遊戲直播、教師講座、相聲表演、詩歌朗誦和廣播節目。其中模型大部分都實現了絲滑過渡,但不知為什麼接替唱歌時好像有點跑調。
研究人員為 MiMo-Audio 設計了少樣本上下文學習評估任務,以評估模型僅依靠上下文語音示例完成語音轉語音生成任務而無需參數更新的能力。該基準測試旨在系統地評估模型在語音理解和生成方面的綜合潛力,其希望觀察到類似於 GPT-3 在文本領域所展示的緊急上下文學習能力。
其功能包括風格轉換、語音轉換、語音翻譯和語音編輯。
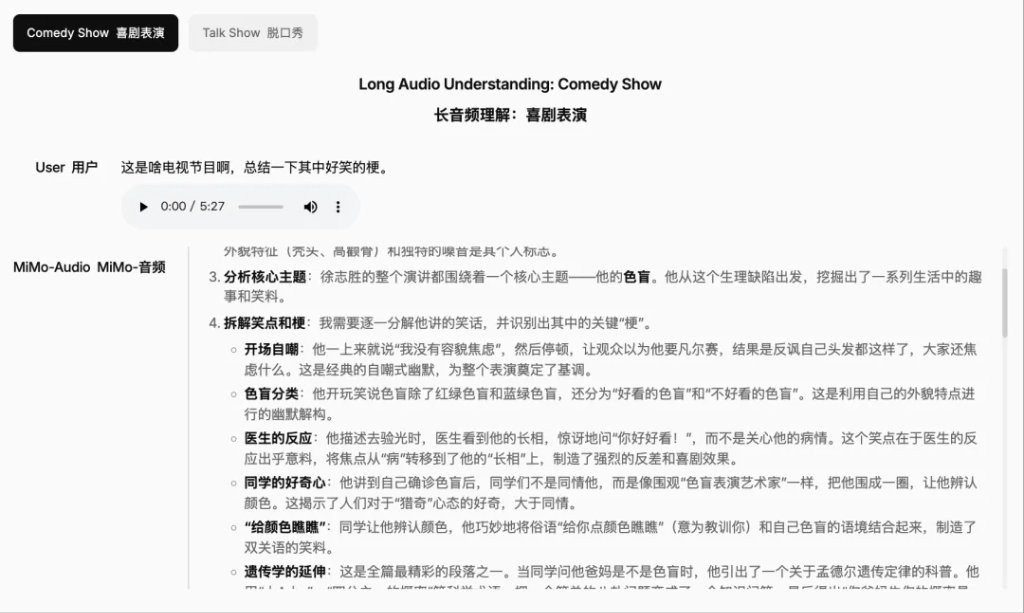
此外,在音頻理解方面,MiMo-Audio 具有音頻字幕、音頻推理、長時間音頻理解功能。
音頻字幕可以提供跨各種領域和場景的音頻內容的詳細描述。

音頻推理可以深入理解和分析複雜的音頻內容,包括上下文識別和邏輯推理。
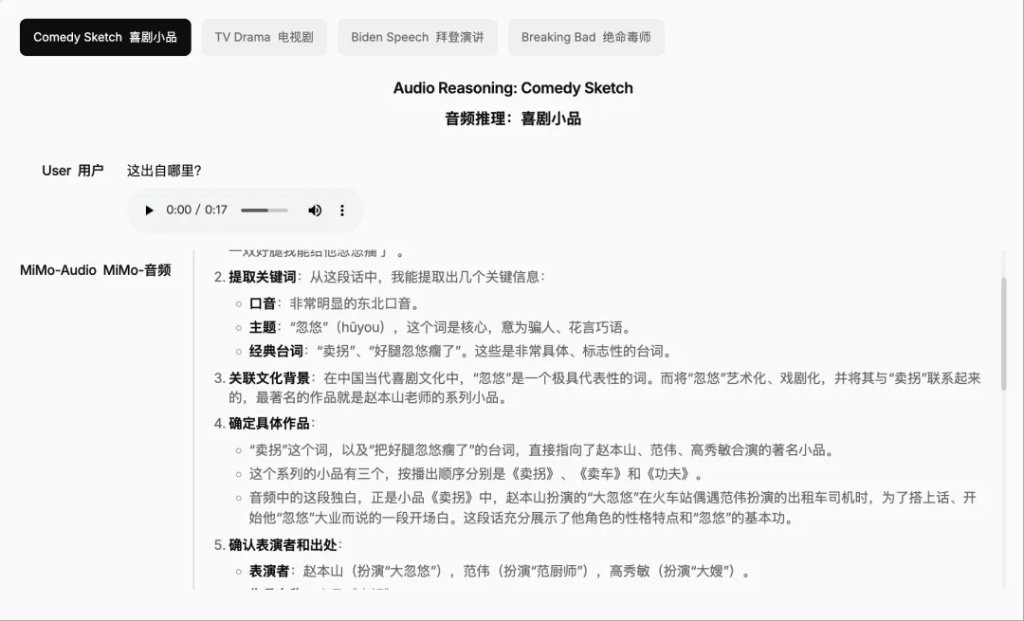
長時間的音頻理解,能夠處理和分析冗長的音頻序列,並具有持續的注意力和連貫的解釋。
MiMo-Audio 集成了 Instruct TTS 功能,並結合了思考模式來優化生成結果。
04.三大技術創新點 評估基準已開源
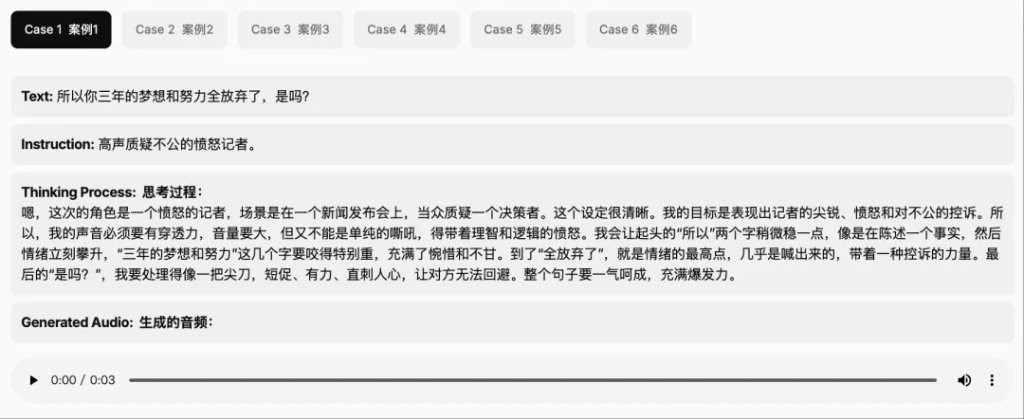
小米官方博客提到,MiMo-Audio 的三個技術創新點在於:
1、首次證明把語音無損壓縮預訓練 Scaling 至 1 億小時可以 “湧現” 出跨任務的泛化性,表現為少樣本學習能力,見證語音領域的 “GPT-3 時刻”;
2、首個明確語音生成式預訓練的目標和定義,並開源一套完整的語音預訓練方案,包括無損壓縮的 Tokenizer、全新模型結構、訓練方法和評測體系,開啓語音領域的 “Llama 時刻”;
3、首個把思考同時引入語音理解和語音生成過程中的開源模型,支持混合思考。
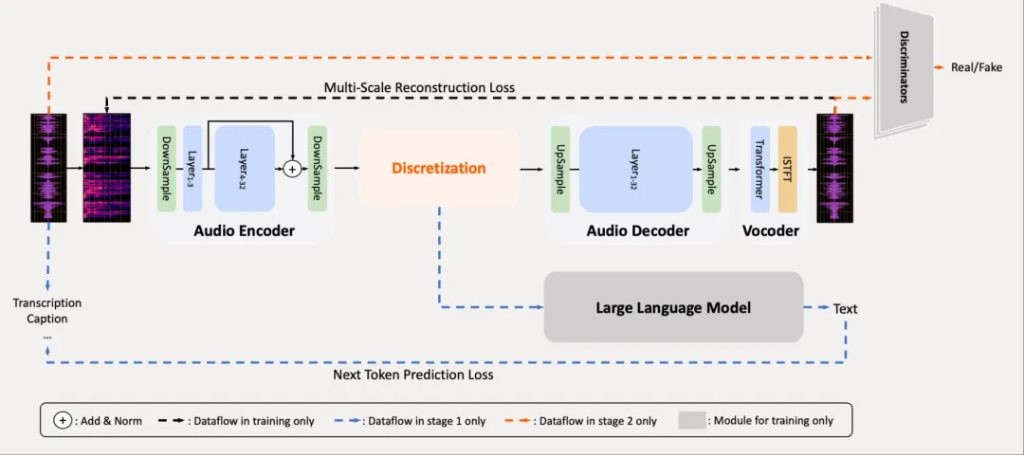
具體來看,現有音頻分詞方法的主要挑戰在於如何有效平衡音頻信號中語義和聲學信息之間的固有權衡,假設音頻分詞器的首要標準是重建保真度,並且它的 token 應該適合下游語言建模,基於此,小米推出了 MiMo-Audio-Tokenizer。
MiMo-Audio-Tokenizer 參數規模是 1.2B,基於 Transformer 架構,包括編碼器、離散化層和解碼器,以 25Hz 幀速率運行,並通過 8 層殘差矢量量化(RVQ)每秒生成 200 個 token。通過整合語義和重建目標,研究人員在 1000 萬小時的語料庫上從頭開始訓練它,在重建質量方面表現較好,並促進了下游語言建模。
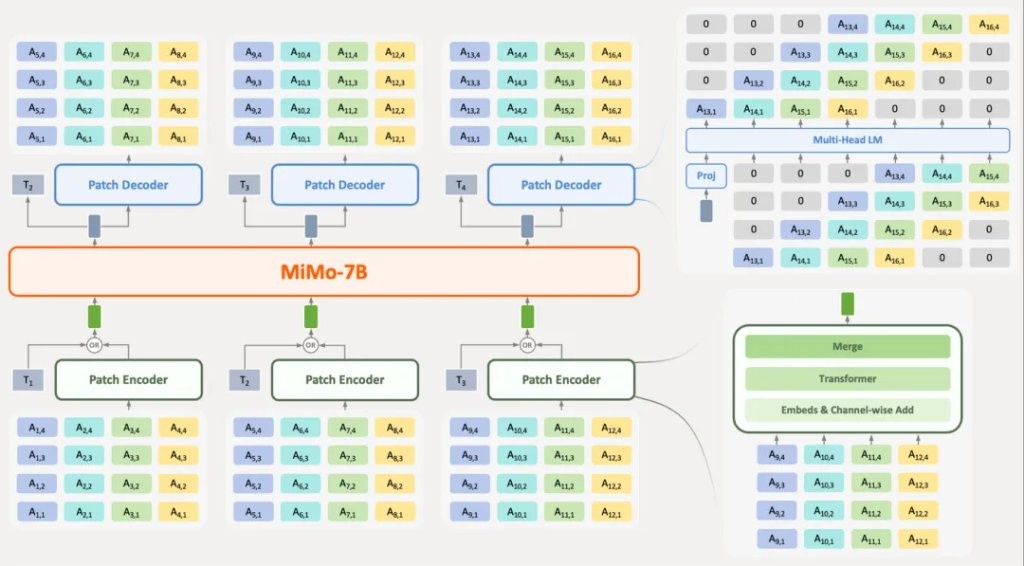
MiMo-Audio 是統一的生成音頻語言模型,它聯合對文本和音頻 token 序列進行建模。該模型接受文本和音頻 token 作為輸入,並自迴歸地預測文本或音頻 token,從而支持涉及文本和音頻模態任意組合的全面任務。
為了提高高 token 率序列的建模效率,並減輕語音和文本模態之間的長度差異,研究人員提出了一種結合補丁編碼器、大模型和補丁解碼器的新型架構。補丁編碼器將 RVQ token 的四個連續時間步長聚合到一個補丁中,將序列下采樣為大模型的 6.25Hz 表示。隨後,補丁解碼器自迴歸地生成完整的 25Hz RVQ token 序列。
此外,小米還開發了全面基準,評估該模型在語音領域的語境學習能力。該基準旨在評估多個方面,包括模態不變的常識、聽覺理解和推理,以及一系列豐富的語音到語音生成任務。
05.結語:小米將持續開源發力語音 AGI
此外小米全面開源的模型、基準評估工具等,可以用來評估 MiMo-Audio 和論文中提到的其他最新音頻大模型,為開發者提供了靈活且可擴展的框架,支持廣泛的數據集、任務和模型。
這一模型的開源也將加速語音大模型研究對齊到語言大模型,為語音 AGI 的發展提供重要基礎,小米官方博客也提到,他們講持續開源,用開放與協作邁向語音 AI 的 “奇點”,走進未來的人機交互時代。
本文作者:程茜,來源:智東西,原文標題:《剛剛,小米最強語音大模型開源!億小時訓練,講脱口秀説快板溜得很》
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
