
AI 硬件暴漲的一晚

AI 硬件暴漲的一晚,DELL 股價上漲 31%,引爆了 AI 領域的投資熱情。NVDA、AMD、MRVL、西部數據、博通等公司的股價也紛紛上漲。美聯儲表示,人工智能可以改善勞動力結果,減少不平等。DELL 訂單增速超過業績確認速度,導致在手訂單增長 3.5 倍。公司上調了 2027 年 AI 服務器的行業總地址。儘管 PC 市場疲軟,但市場仍然看好 AI 領域的發展。
DELL +31% 引爆 AI,都在尋找 catch-up plays
軟件和雲都沒咋動,硬件尤其是 Semi 全在漲。NVDA+4%,AMD+5%,MRVL+8%,西部數據 +8%,博通 +7%(Oppenheimer、BofA 提目標價),台積電+4%,鎂光 +5%,超威盤後 +14%(納入指數)。除了 PMI 數據和美債,美聯儲今天都提了 AI:"AI could improve labor outcomes, reduce inequality”
感受下來自 sell side 們的熱情:
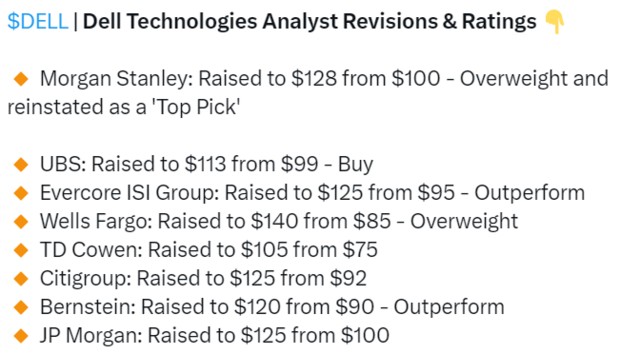
這些都是反光鏡,不得不提一下海通國際 Jeff 10 天前的 print,事實證明,市場的確就是在找 AI catchup plays

大摩對 DELL 訂單做的流水圖,非常清晰,説到底,新增訂單增速遠快於業績確認速度(交付速度),導致到今天 Backlog(在手訂單)已經是 6 個月前的 3.5 倍...上個季度擔心的 GPU lead time 耽誤收入確認,現在 H100 lead time 縮短成利好
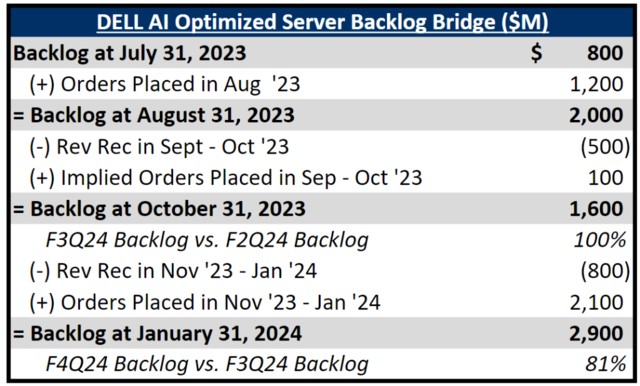
最關鍵的,公司跟 TSMC AMD 也學會了,出來上調一把行業 TAM,2027 年 AI 服務器 1520 億美元(之前 1240 億美元)。2027 幾顆衞星開始腳踩腳了。負面也有,PC 市場疲軟和傳統服務器的競爭激烈定價壓力,復甦要到下半年出現,整體毛利率也有壓力(成本上升和 AI 稀釋)。不過看市場基本選擇了 look through,都在找 lagger,已知的傳統疲軟似乎基本 price in 了。估值便宜 + 分紅又提升了 20%...
citi 也發了業績會後的 callback,要點:
指引:對於 2025 財年(24CY)的指引好於預期,預計全年大幅增長,對服務器中 AI 勢頭的樂觀,傳統服務器的反彈,以及下半年 PC 和存儲的復甦持樂觀態度。
服務器:積壓訂單中 GPU mix(H100/H200/MI300X),以及他們 lead time mix 的不同,將導致 AI 服務器在季度間收入確認上的不均勻(H100 確認加速,新產品確認估計又受交付限制)。29 億美元的積壓訂單中 H200 和 MI300x 佔比在提升。管理層希望在第一季度儘可能多地出貨 H100,H100 的交貨時間已經從第三季度的 39 周下降。
毛利率:預計 2025 財年的毛利率將下降,這是由於存儲 mix 比例下降、大宗商品成本增加、更多價格競爭(PC、傳統服務器),以及預計將出貨更多的 AI 服務器(AI 服務器會稀釋毛利率)。
此外 NTAP(美國網存)業績超預期,其實 beat 幅度不大,但股價 +18%,因為也在提 AI...NTAP 在業績會上重點強調進了英偉達 DGX PODs 中的 “多個” 項目...
AMD 除了傳的小段子,看下來 1)YTD 英偉達 65%,AMD 35%,可能就是追一追;2)8bn 是否得到默許了不確定,但如果推理真的要引爆,那就水漲船高陽光普照了...
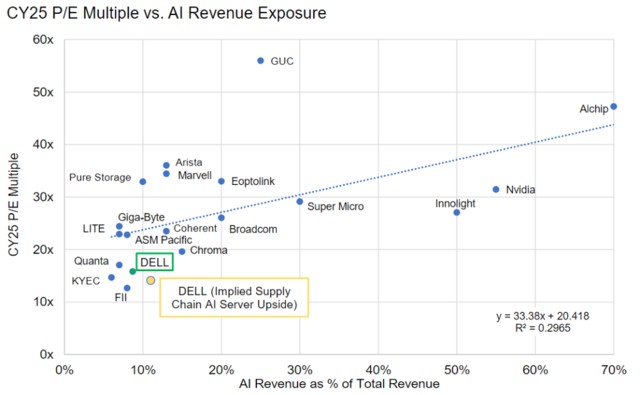
總之現在市場對 AI 的追逐,或者説尋找 “AI 新標的” 的熱情極其高漲。MS 搞了個 AI 股票座標系,橫軸 AI 收入佔比%,縱軸是 25 年 PE multiple。靜態去看的話,當然是越處於東南方向的越好。動態去看的話,大家都會往右邊走,誰能保持在趨勢線下方就是價格更划算。其實這種座標系,潛台詞就是 AI 佔比越高市場給與更多追逐從而會帶來更高估值溢價。那處於趨勢線下方的且偏離較遠的,都是 “潛力股”。
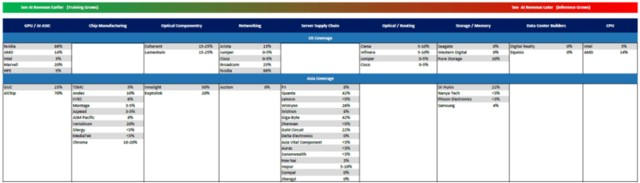
標的不夠?MS 給了另一張圖,IDC 裏面各個公司的 AI 收入佔比:
推理需求到了 70%?
上週末 The wire 對 Jensen 的採訪廣泛傳播,但其中一個細節被修改了(來自讀者 Dai 的提醒),很微妙。原文中 Jensen 表示 “如果我猜的話,Nvidia 今天的業務可能是 70% 的推理,30% 的訓練。” 之後似乎是被公關修改了:

言之鑿鑿的 70%,再考慮上下文,不像是口誤,更像是説漏了。被公關也合理,畢竟和財報披露口徑差別太大。而且 Dai 分析很有道理,全年 40%,年初很低的話,年末到了 70% 也很合理。
Alchip 世芯業績會上要點
ASIC 市佔率已經是純 ASIC 公司第一名,就算跟 MTK、AVGO、MRVL 比,也只輸給 AVGO;來自最大客户(亞馬遜)的 PO 持續上升,相比之前要上修了,且這顆新的 chip 生命週期和需求都比之前預期的要大。客户給的 5nm 新產品的 forecast "too good to be true"
國產 HBM 的一份紀要
國內良率 50-60% 對比海外 85%(但國內是中試線,做成量產線良率會提升很多);國內兩派,一個大家知道的 XXXX,一個是 H+XX+XX(具體放星球了)。項目定義是 3,可能要到 26 年出產品,也可能比這個更早。
馬斯克除了起訴 OpenAI,今天還有個發言,增量:
我從未見過任何技術進步得像 AI 這麼快,目前 AI 的增長接近每六個月增加十倍(我理解是計算量)。這就是為什麼英偉達的市值如此巨大,他們擁有最好的 AI 芯片,它的市值還可能會更高,AI 芯片熱潮會比任何曾經的淘金熱都要大。我認為我們真的處於可能是有史以來最大的技術革命的邊緣。
我們離完全自動駕駛非常接近;乘用車的平均使用時間大約是每週 10 小時,但如果實現了自動駕駛,每週使用時間可以達到 50 到 60 小時,這意味着乘用車的效用將增加五倍
張忠謀:“有人跟我要 10 個 fabs”
最近在日本一個會議上表示,有人跟他説,需要 10 個 fab 來生產 AI 芯片,“他們談論的不是 wafers,而是 fabs” 張忠謀認為 10 fabs 過於驚人,真實的需求可能在 幾萬片晶圓~10 個 fabs 之間,更為合理(但這個範圍也很大,也就是幾萬~百萬片量級之間,參考英偉達 2024 需求可能也在 10 萬片以上了)
月之暗面楊植麟訪談長文,乾貨滿滿,省流:
Scaling law 為什麼能成為第一性原理?你只要能找到一個結構,滿足兩個條件:一是足夠通用,二是可規模化。通用是你把所有問題放到這個框架建模,可規模化是隻要你投入足夠多算力,它就能變好。這是我在 Google 學到的思維:如果能被更底層的東西解釋,就不應該在上層過度雕花。有一句重要的話我很認同:如果你能用 scale 解決的問題,就不要用新的算法解決。新算法最大價值是讓它怎麼更好的 scale。當你把自己從雕花的事中釋放出來,可以看到更多。
長文本是登月第一步,因為足夠本質,它是新的計算機內存。老的計算機內存,在過去幾十年漲了好幾個數量級,一樣的事會發生在新的計算機上。它能解決很多現在的問題。比如,現在多模態架構還需要 tokenizer(標記器),但當你有一個無損壓縮的 long context 就不需要了,可以把原始的放進去。進一步講,它是把新計算範式變成更通用的基礎。舊的計算機可以 0、1 表示所有,所有東西可被數字化。但今天新計算機還不行,context 不夠多,沒那麼通用。要變成通用的世界模型,是需要 long context 的。第二,能夠做到個性化。AI 最核心的價值是個性化互動,價值落腳點還是個性化,AGI 會比上一代推薦引擎更加個性化。但個性化過程不是通過微調實現,而是它能支持很長的 context(上下文)。你跟機器所有的歷史都是 context,這個 context 定義了個性化過程,而且無法被複刻,它會是更直接的對話,對話產生信息。
scaling law 走到最後發現根本走不通的概率幾乎為 0。模型可擴展的空間還非常大,一方面是本身窗口的提升,有很長路要走,會有幾個數量級。另一方面是,在這個窗口下能實現的推理能力、the faithfulness 的能力(對原始信息的忠實度)、the instruction following 的能力(遵循指令的能力)。如果這兩個維度都持續提升,能做非常多事。可能可以 follow(執行)一個幾萬字的 instruction(指令),instruction 本身會定義很多 agent(智能體),高度個性化。
AI 不是我在接下來一兩年找到什麼 PMF,而是接下來十到二十年如何改變世界——這是兩種不同思維
開源的開發方式跟以前不一樣了,以前是所有人都可以 contribute(貢獻)到開源,現在開源本身還是中心化的。開源的貢獻可能很多都沒有經過算力驗證。閉源會有人才聚集和資本聚集,最後一定是閉源更好,是一個 consolidation(對市場的整合)。如果我今天有一個領先的模型,開源出來,大概率不合理。反而是落後者可能會這麼做,或者開源小模型,攪局嘛,反正不開源也沒價值。
從 GPT-3.5 到 GPT-4,解鎖了很多應用;從 GPT-4 到 GPT-4.5 再到 GPT-5,大概率會持續解鎖更多,甚至是指數型的應用。所謂 “場景摩爾定律”,就是你能用的場景數量會隨着時間指數級上升。我們需要邊提升模型能力,邊找更多場景,需要這樣的平衡。它是個螺旋。
可以理解成有兩種不同壓縮。一種是壓縮原始世界,這是視頻模型在做的。另一種是壓縮人類產生的行為,因為人類產生的行為經過了人的大腦,這是世界上唯一能產生智能的東西。你可以認為視頻模型在做第一種,文本模型在做第二種,當然視頻模型也一定程度包含了第二種。它最終可能會是 mix,來建立世界模型。
硅谷一直有一個爭論:one model rules all 還是 many specialized smaller models(一個通用模型來處理各種任務,還是採用許多專門的較小模型來處理特定任務),我認為是前者。
(完)
本文作者:Jason,來源:信息平權,原文標題:《AI 硬件暴漲的一晚》
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
