
AI 能代替人类工作了吗?汇丰做了个实验

滙豐直言,人類分析師 +AI 工具才是提升工作效率的關鍵,AI 會在關鍵地方犯錯,每一個步驟都需要人類確認。
AI 之火的燎原之勢延續至 2024 年,甚至任何不運用 AI 的人都開始被貼上了 “時代落後者” 的標籤。
2 月 20 日,滙豐發佈了一份題為《AI 能代替我工作嗎?》的實驗分析報告,在報告中,滙豐數據科學與分析主管 Mark McDonald 比較了 ChatGPT 的 “高級數據分析” 模塊與人類分析師的表現,得出結論:
此次試驗中,AI 的表現非常好且仍在不斷進步,但還未到能取代數據分析師的水平,AI 的運用更傾向於實現特定任務的自動化,而不是完全替代人類的全部職責和工作。數據分析師在藉助 AI 工具後,生產力的水平已經得到了顯著提升。
滙豐稱,在實驗過程中,他們採用了一個公開的數據集——各州 Zillow 房屋價值指數,讓人類數據科學家和 ChatGPT 分別對該數據集進行探索性數據分析 (EDA)。
滙豐認為,上述任務對於 AI 工具(如 ChatGPT)來説是一個挑戰,原因如下:
- 指令模糊:要求不是特別明確,沒有具體指出要分析數據集的哪些方面,這要求 AI 能夠自主決定如何進行 EDA。
- 需要進行多步驟分析:進行 EDA 分析,不僅僅是執行一個簡單的任務,而是需要通過多個分析步驟來探索數據集的特性和趨勢。
- 數據格式非典型:數據集的格式並不是常見的標準格式,這增加了處理和分析數據的複雜性。
來看實驗的結果,滙豐寫到,最開始他們僅僅是將數據集加載到 ChatGPT 的對話框中,並要求其對數據集進行探索性數據分析(EDA),這種嘗試通常以 ChatGPT 僅執行了幾項 EDA 分析後崩潰而告終。
為了使實驗更加順利,滙豐發現首先要羅列出希望 ChatGPT 完成的 EDA 分析步驟,然後逐步進行。但每個步驟都需要人工參與確認,才能展現 AI 最佳性能,人類的參與可以更好的配合 AI 正確高效完成任務。
AI 分析師與人類分析師工作對比
滙豐在報告中稱,他們將 Zillow 各州房屋價值指數 (ZHVI) 的數據文件上傳到 ChatGPT,並要求它將數據加載到 pandas DataFrame 中。然後,讓 ChatGPT 分步驟對該數據集進行全面探索性數據分析 (EDA)(完整步驟見附錄)。
與此同時,滙豐也讓人類分析師執行了相應的步驟,以此來比較人類和人工智能各自在數據分析領域的優缺點:
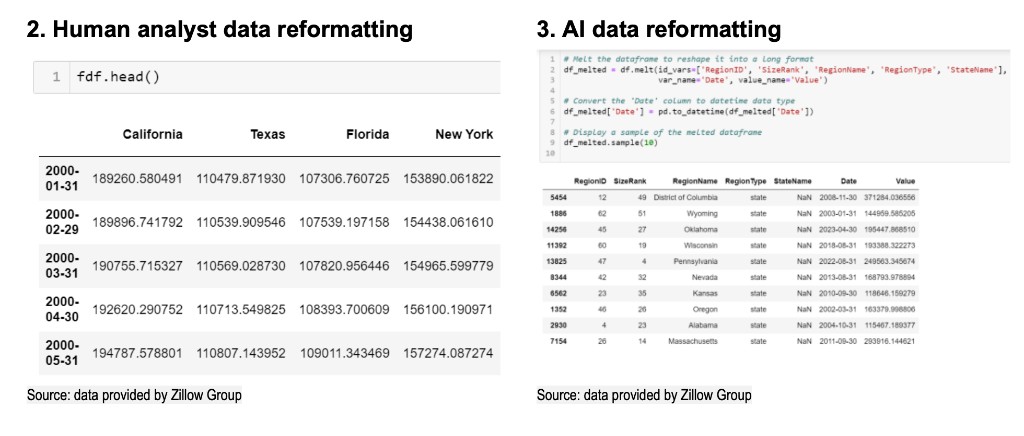
首先在數據處理過程中,人類分析師採取的方法是進行數據行列轉置(dataframe),運用這種方法,原來作為列名的日期變為索引值,原來的 RegionName 列的值變成了新的列名。這樣做的結果是丟失了其他元數據列(如 RegionID, SizeRank, RegionType 和 StateName),這些信息被放到了一個單獨的元數據對象中。
AI 採取的方法是在 pandas 中使用 melt 函數,來將寬格式的數據框轉換為長格式,melt 方法的好處是所有元數據都保留在同一個數據框對象中。
在這個例子中,元數據並不是特別有用,所以兩種方法都可行。但在其他元數據更為重要的數據集中,人類分析師的方法可能需要後續在分析中執行大量的聯接或合併操作,會比較麻煩。
與此同時,AI 在寫代碼的過程中會有大量的註釋,這有助於理解代碼的目的和功能。相比之下,人類在進行數據分析的過程中往往不願意花時間寫註釋,因為這會佔用較多時間。
但 AI 生成的代碼中存在較多的註釋對於提高代碼質量和促進團隊間的協作是有益的,雖然人類不喜歡寫註釋,但他們很喜歡看別人的代碼時能看到這些註釋。
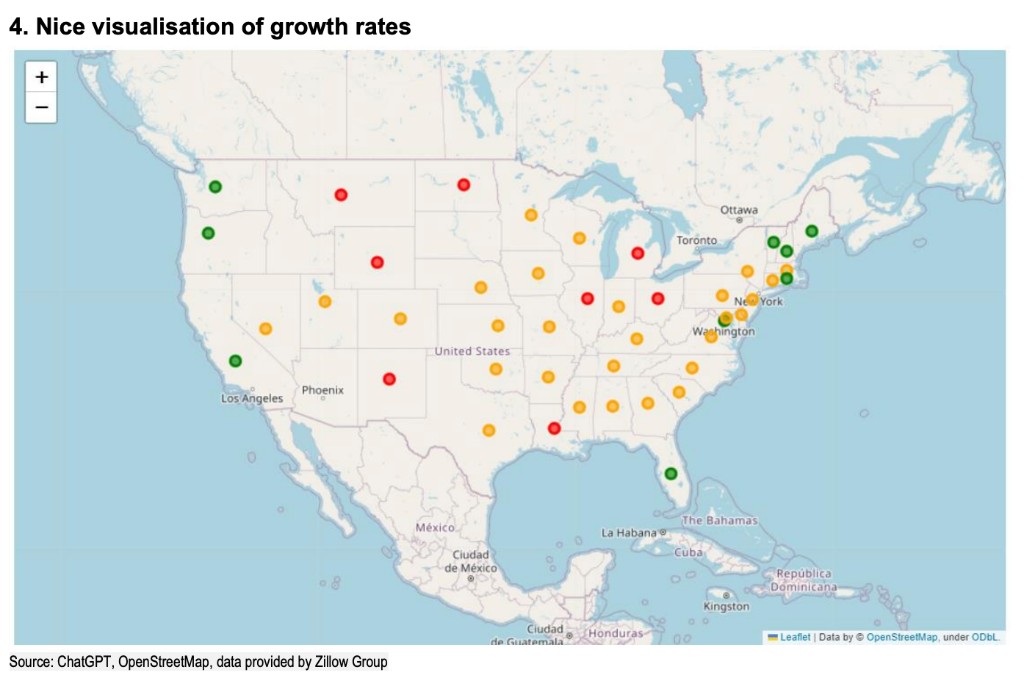
滙豐在報告中指出,AI 做的最讓人印象深刻的事情就是在地圖上直觀顯示各州房價的增長率,下圖僅展示了這一可視化的截圖,而實際上這是一個交互式的 HTML/Javascript 地圖:
這也是 AI 如何和人類分析師有效合作的案例,下圖所示的案例中,AI 使用了一個名為 folium 的 Python 包來創建可視化地圖,這是人類分析師未曾使用過的工具,但通過查看 AI 生成的代碼和完整的工作示例,人類分析師能夠迅速學習如何創建類似的可視化效果。
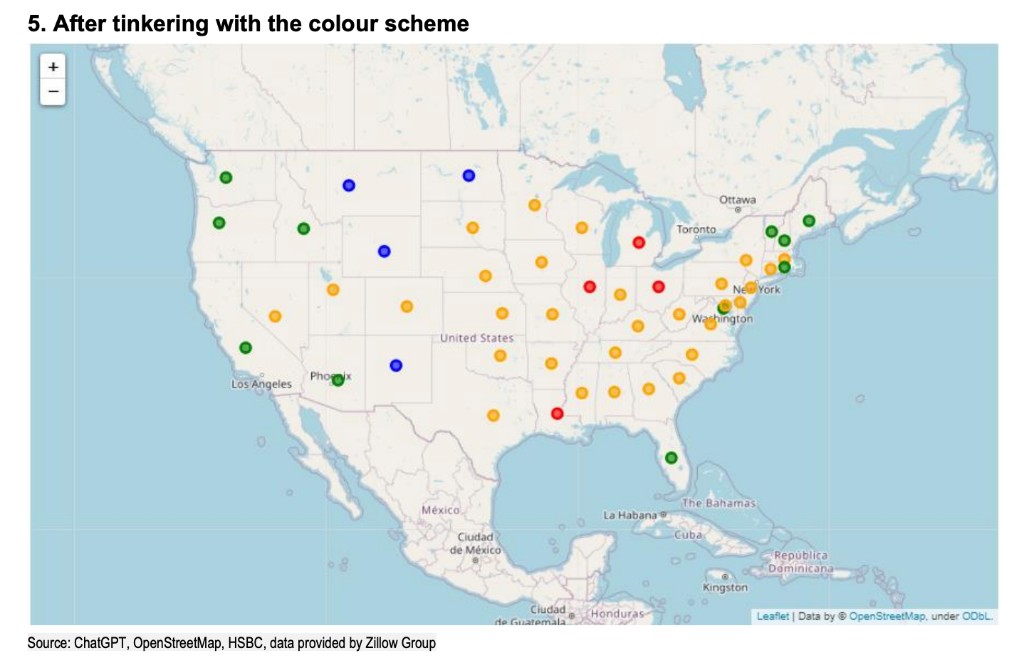
同時,在 AI 生成可視化交互圖中存在一個問題,即缺失數據的顏色編碼與表示低增長率的顏色編碼相同,這會引起混淆。人類分析師通過修改 AI 的代碼,很好的解決了這個問題,改進後的可視化圖例如下,其中用藍色標出了缺失數據的州,這樣使得可視化信息更加清晰易懂。
滙豐稱,當 AI 在進行相關性分析時犯了一個沒有受過專業訓練的數據分析師會犯的錯——在非平穩數據上計算相關性的錯誤,選擇了基於價格水平而不是價格變化的百分比來分析:
儘管 AI 熟悉計量經濟學的文獻,能夠建議對數據應用 ARIMA 模型,但它仍然犯了一個在非平穩數據上計算相關性的錯誤。這一點也表明了 AI 與人類在處理知識方面的不同。
人類一旦在計量經濟學方面受到良好的訓練,通常不會再犯這樣的錯誤,而 AI 儘管知道相關理論,但在實際應用中仍然可能犯錯。在使用 AI 進行數據分析時,仍然需要人類專家的監督來避免得出錯誤或危險的結論。
我們再次要求 AI 使用價格環比百分比變化而不是價格本身進行分析。這次分析的結果可以看到非平穩數據的重要性。
當使用非平穩數據(即價格水平)進行相關性評估時,AI 錯誤評估德克薩斯州和夏威夷州之間的相關係數(高達 94%)。而當分析方法被修正後,這兩個州之間的相關係數降至 58%。
滙豐稱在最後的房價預測階段,AI 選擇並運用 ARIMA 模型來預測加州房價,但 AI 在選擇模型參數時存疑,它隨意選擇了一個 ARIMA(5,1,0) 模型進行擬合,沒有提供為何選擇這個模型的理由。
而運用 AI 時還有一個關鍵問題,隨着時間流逝AI 已經忘記了它最初計劃的 EDA 步驟,因此人類不得不提醒 AI 按計劃進行,AI 的任務才得以繼續完成。
以下為滙豐讓 ChatGPT 完成分析步驟的拆解:
1. 數據概覽:
顯示數據集的前幾行和後幾行。檢查每列的數據類型和非空值計數。獲取數值列的基本數據摘要。2. 處理缺失值:
識別有缺失值的列。採用適當的策略來處理這些問題,如刪除空值數據或給空值賦值。3. 時間分析:
繪製房價總體變化趨勢。識別週期性或循環趨勢。高亮異常點或異常事件。4. 地區分析:
識別平均房價最高和最低的州。分析各州的增長率,找到增長最快和下降最快的市場。如果可能,在地圖上可視化數據,發現區域分佈圖。5. 分佈分析:
繪製直方圖或核密度分佈估算圖,以瞭解房價的分佈情況。
使用箱形圖識別異常值並比較不同州之間的分佈。6. 相關性分析:
計算不同州之間房價的成對相關性,識別關係。使用熱圖可視化相關性。7. 分解:
如果數據集顯示明顯的趨勢或週期性,進行時間序列分解,分離趨勢、週期性和殘差。8. 頻率分析:
分析房價大幅上漲或下跌的頻率。識別出現峯值或低谷的特定月份或季節。9. 統計測試:
根據問題或假設,進行適當的統計檢驗。例如,如果要知道兩個州之間的價格差異是否具有統計學顯著性意義,可以使用 t 檢驗。10. 特徵工程(如果計劃建模):
創建滯後特徵、移動均值和其他衍生特徵,這些特徵對預測建模可能有用。11. 洞察和記錄:
在探索性數據分析的過程中,記錄所有重要的發現和見解。這對後續決策或結果展示很有用。12. 可視化:
使用各種可視化工具和技術,以直觀和深刻的方式表示數據,包括線圖、條形圖、散點圖、熱圖等。13. 最終報告:
總結關鍵的分析結果,提供基於分析的可操作性建議或推薦。
