
“GPT-4 變傻” 不只是 OpenAI 的苦惱,所有大模型與人類交往越久就會越蠢?

ChatGPT 發佈一年多,已經在全世界累積了超過 1.8 億用户。但最近關於 GPT-4 在 “變笨”、“變懶” 的説法不斷。研究發現,大模型在處理早期數據時展現出的優異表現實際上是受到了「任務污染」的影響。這種污染使得大模型更像是一種檢索的模擬智能方法,回答問題全靠記,而非純粹基於學習理解能力。許多大模型在處理早期數據時表現出色是因為它們在預訓練數據中已經 “見過” 這些任務。
ChatGPT 發佈一年多,已經在全世界累積了超過 1.8 億用户。而隨着越來越多的人們開始頻繁使用它,近幾個月關於 GPT-4 在 “變笨”、“變懶” 的説法不絕於耳。
大家發現這個昔日大聰明在回答提問時逐漸失去了最初的理解力和準確性,時不時給出 “驢唇不對馬嘴” 的答案,或是乾脆擺爛、拒絕回答。
對於 GPT-4 降智的原因,用户們有許多自己的猜測。而最近,來自加州大學聖克魯茲分校的一篇論文,給出了學術界的最新解釋。

「我們發現,在 LLM 訓練數據創建日期之前發佈的數據集上,LLM 的表現出奇地好於之後的數據集。」
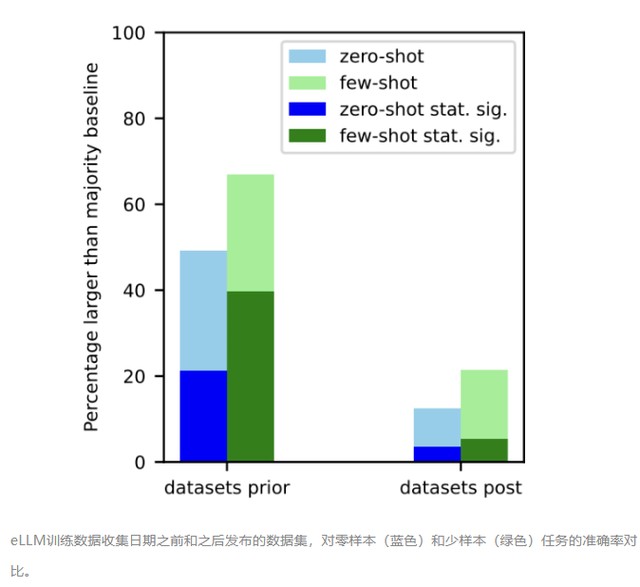
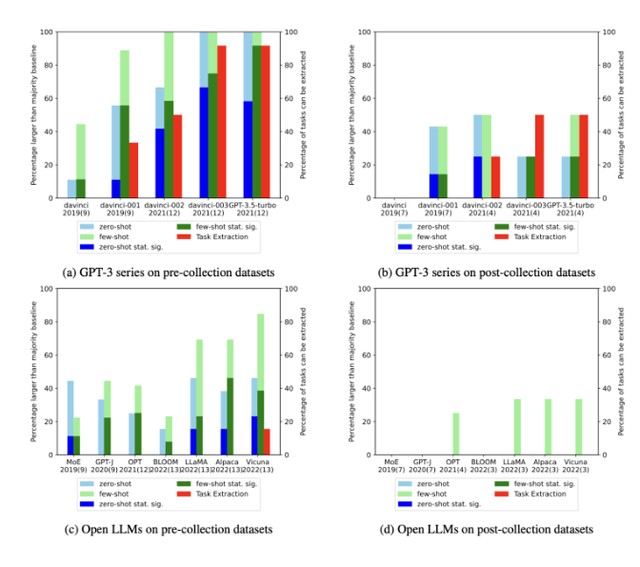
eLLM 訓練數據收集日期之前和之後發佈的數據集,對零樣本(藍色)和少樣本(綠色)任務的準確率對比。
因此論文認為,許多大模型在處理早期數據時展現出的優異表現,實際上是受到了「任務污染」的影響。
我們知道,大語言模型之所以強大,是因為在各種零樣本和少樣本任務中表現出色,顯示出處理複雜和多樣化問題的靈活性。
而「任務污染」就是一種對零樣本或少樣本評估方法的污染,指在預訓練數據中已包含了任務訓練示例——你以為 GPT 初次回答就這麼得心應手?No!其實它在訓練過程中就已經 “見過” 這些數據了。
評估的模型與數據集
由於封閉模型不會公開訓練數據,開放模型也僅提供了數據源,爬取網站去獲取數據並非易事,所以想簡單驗證是困難的。
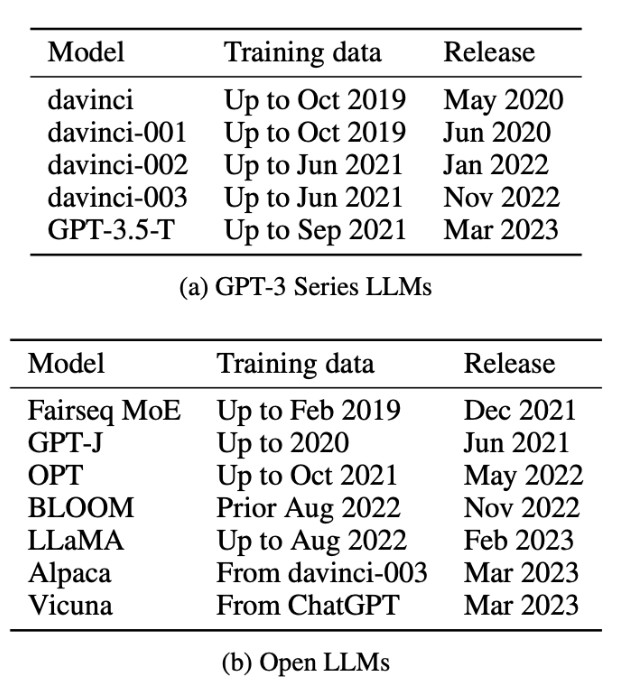
為了實測任務污染的範圍,論文中共評估了 12 種不同的模型,包括 5 個 GPT-3 系列封閉模型和 Fairseq MoE、Bloom、LLaMA 等 7 個開放模型,並列出訓練集創建和模型發佈日期。
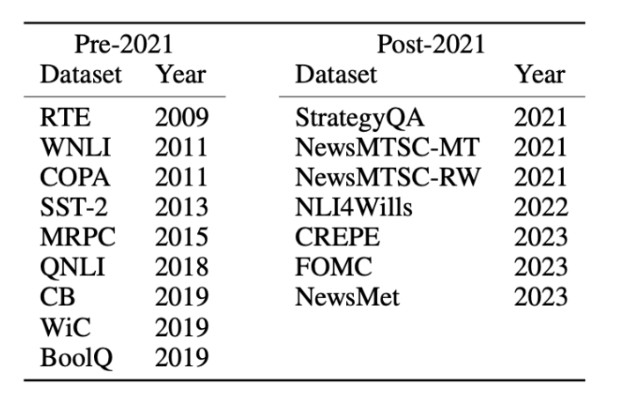
在數據集上則劃分為兩類:2021 年之前和 2021 年之後發佈的數據集。以此來對比新老數據集之間的零樣本或少樣本任務性能差異。
四種測量方法
基於以上樣本,研究人員採用了四種方法來衡量大模型的任務污染範圍。
1. 訓練數據檢查:直接搜索訓練數據以找到任務訓練示例。
發現經過微調的 Llama 模型 Alpaca 和 Vicuna,在訓練中加入少量任務示例後,對比原版 Llama 性能有所提升。
2. 任務示例提取:從現有模型中提取任務示例。
具體方法是通過提示詞指令,讓模型生成訓練示例。由於在零樣本或少樣本評估中,模型本不應該接受任何任務示例訓練,所以只要 LLM 能夠根據提示生成訓練示例,就是任務污染的證據。
結果發現,從 GPT-3 第一代 davinci-001 到後來的 3.5-T,代表可以生成訓練示例的紅色 X 越來越多了,證明任務污染越發嚴重。

3. 成員身份推斷:僅適用於生成任務,核心是檢查模型為輸入示例生成的內容是否與原始數據集完全相同。如果一致,就可以認定這個示例是 LLM 訓練數據的成員。
因為如果在開放式生成任務中出現這種精準匹配,那模型無異於具備了預知能力,能準確復現數據集中的具體措辭,表現可以説是 “天秀” 了,這就強烈暗示了模型在訓練時已經學習過這些內容。
結果顯示在 GPT-3 系列和最近開源的大模型中,這種生成內容與原始數據完全相同的情況普遍存在,且污染程度隨時間呈上升趨勢。
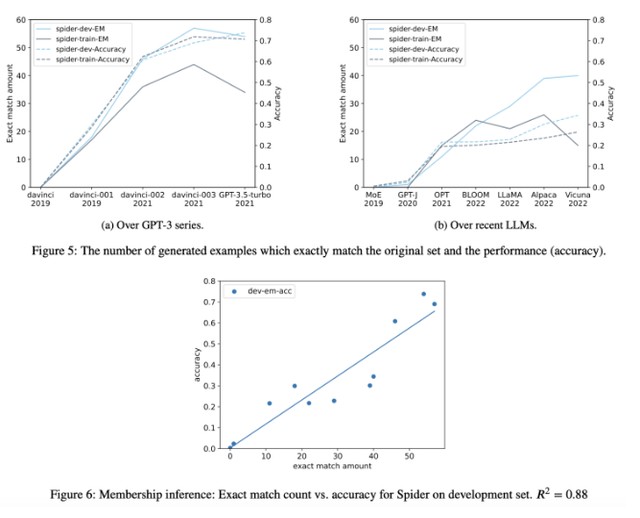
4. 時間序列分析:對於已知訓練數據收集時間的模型,測量其在已知發佈日期的數據集上的性能,並使用時間序列證據檢查污染的證據。
通過對所有數據集和 LLM 進行全球性的時間序列分析,發現對於在 LLM 發佈之前收集的數據集(左側),無論是零樣本還是少樣本任務中,擊敗多數基線的可能性都遠遠更大。
最終結論
在所有實驗過後,論文給出如下關鍵結論:
- 由於任務污染,閉源模型在零樣本或少樣本評估中的性能表現被誇大了,特別是那些經過人類反饋的強化學習(RLHF)或指令微調的模型。由於污染程度仍然未知,我們需要謹慎對待。
- 在實驗中,對於沒有展示出污染可能性的分類任務,大模型在零樣本和少樣本設置裏很少顯示出相對多數基線在統計學意義上的顯著性改進。
- 隨着時間推移,GPT-3 系列模型在許多下游任務的零樣本或少樣本性能上的提升很可能是由於任務污染造成的。
- 即使是開源的 LLM,出於多種原因,檢查訓練數據的任務污染也可能是困難的。
- 鼓勵公開訓練數據集,以便更容易診斷污染問題。
GPT“變笨” 不孤單,所有大模型殊途同歸?
讀過論文後,許多網友也悲觀地表示:降智沒準兒是目前所有大模型的共同命運。
對於沒有持續學習能力的機器學習模型來説,其權重在訓練後被凍結,但輸入分佈卻不斷漂移。近兩億用户五花八門的新問題日夜不間斷,如果模型不能持續適應這種變化,其性能就會逐步退化。

就比如基於大模型的編程工具,也會隨着編程語言的不斷更新而降級。
而持續重新訓練這些模型的成本很高,人們遲早會放棄這種效率低下的方法。就目前的 LLM 來説,很難構建可以在不嚴重干擾過去知識的情況下,連續適應新知識的機器學習模型。
有網友認為:“圍繞人工智能的所有炒作大多是基於這樣一個假設:人工智能將會越來越好。但按照這些大型語言模型的設計方式,實現通用人工智能幾乎是不可能的。在特定場景下的小眾用例是這項技術的最佳使用方式。”
而持續學習,恰恰是生物神經網絡的優勢。由於生物網絡具有強大的泛化能力,學習不同的任務可以進一步增強系統的性能,從一個任務中獲得的知識有助於提升整個學習過程的效率——這種現象也稱為元學習。
“從本質上講,你解決的問題越多,就會變得越好,而大模型雖然每天被數以百萬計的問題所觸發,它們並不會自動地在這些任務上變得更加出色,因為它們的學習能力被凍結在了某一時刻。”

不過想來一個有些矛盾的現實是,現在的人們越來越依賴於 AI 生成的內容,用退化中的大模型提供的答案去解決生活中的實際問題。未來大模型爬到的數據,將會越來越多會是它自己創造的東西,而不是來自人腦。
AI 用 AI 的產出去自我訓練,最終結果又會走向何方呢?如果不着手從根本上解決數據污染和持續學習能力的問題,未來的世界會和大模型一起變笨嗎?
風險提示及免責條款
市場有風險,投資需謹慎。本文不構成個人投資建議,也未考慮到個別用户特殊的投資目標、財務狀況或需要。用户應考慮本文中的任何意見、觀點或結論是否符合其特定狀況。據此投資,責任自負。
